自2022年11月30日ChatGPT问世,大语言模型在全球掀起热潮,众多高校、科研机构及AI企业纷纷投身其中,探索其在各行业的应用潜力与创新模式。
作为国内机器翻译领域深耕多年的技术团队,我们曾率先成功推出统计机器翻译及神经网络机器翻译服务,并持续迭代。
1、凭借丰富的业务生态与深厚的技术积累,2023年伊始,有道迅速开启以“应用落地” 为导向的翻译大模型自研之路。
2、经过持续的技术攻关和优化迭代,2023年6月,“子曰翻译大模型1.0”正式推出;
3、2024年5月,实现“子曰翻译大模型1.5”上线部署,至今已过去七个月。期间有道翻译的用户们积极使用我们的服务,并且慷慨地分享了众多极具价值的反馈与建议。
如今,子曰翻译大模型2.0已正式与大家见面,这象征着我们在语言翻译技术的征途上又迈出了坚实而重要的一步,相信能够为我们的用户带来更加出色的翻译体验。
从1.5到2.0, 质的飞跃
整体性能上,子曰翻译大模型 2.0 相较于1.5版本实现了质的飞跃。这背后,是我们从数据、算法以及评估三个关键维度所展开的深入探索与系统性升级。
在数据层面,为训练面向翻译任务的基座模型,我们精心收集了并严格清洗了数千万高质量的翻译数据。不仅确保了数据的准确性与适配性,为模型训练打下了牢固的根基,更极大地丰富了数据资源库,让模型在多样化翻译场景中游刃有余。此外,我们基于海量的翻译提示进行了精细化的人工标注,有效地提升了数据标注的质量,为模型执行翻译任务提供了精准的指导。
在算法层面,以子曰教育大模型为基础,我们进行了二次预训练,成功打造出了更具专业性与针对性的翻译基座大模型,显著提升了翻译性能。这其中,我们运用了先进的大模型蒸馏技术,让模型在精简参数的同时,运行效率与推理速度大幅提升;创新性地使用了大模型融合技术,将多个模型优势进行整合,进一步增强了翻译的准确性与稳定性;我们还实现了基于人类偏好的翻译数据自动获取,并以此进行强化学习;通过引入Online DPO技术,动态调整模型生成策略,保证了译文的质量与流畅度的提升。此外,多任务联合学习的开展,让模型能够在多个翻译任务中协同进步,综合翻译能力得到了显著增强。
在评估层面,我们人工标注了覆盖各个领域的开发集和盲测集,严格确保了测试数据的全面性和代表性。我们对算法团队所使用的开发集和盲测数据集实行严格分离、相互独立,以确保评估的客观性与准确性,模型最终效果以盲测集效果为准。在自动指标评估上,除了基于comet的自动化指标,我们还自主训练了超越comet准确率的基于大模型的翻译评估模型,为性能评估提供更可靠依据。同时,我们设计并执行了更完善的人工评估方案,从多维度对模型的翻译结果进行细致地分析和评价。
正是通过这三个层面的全方位优化与升级,子曰翻译大模型2.0在翻译质量、效率以及鲁棒性等方面实现了质的飞跃,能够为用户带来更优质、精准的翻译服务。
性能远超国内外通用大模型及专用翻译模型
为了展示子曰翻译大模型 2.0 的性能,我们在WMT以及Flores200的测试集上进行了中英互译的基准测试。

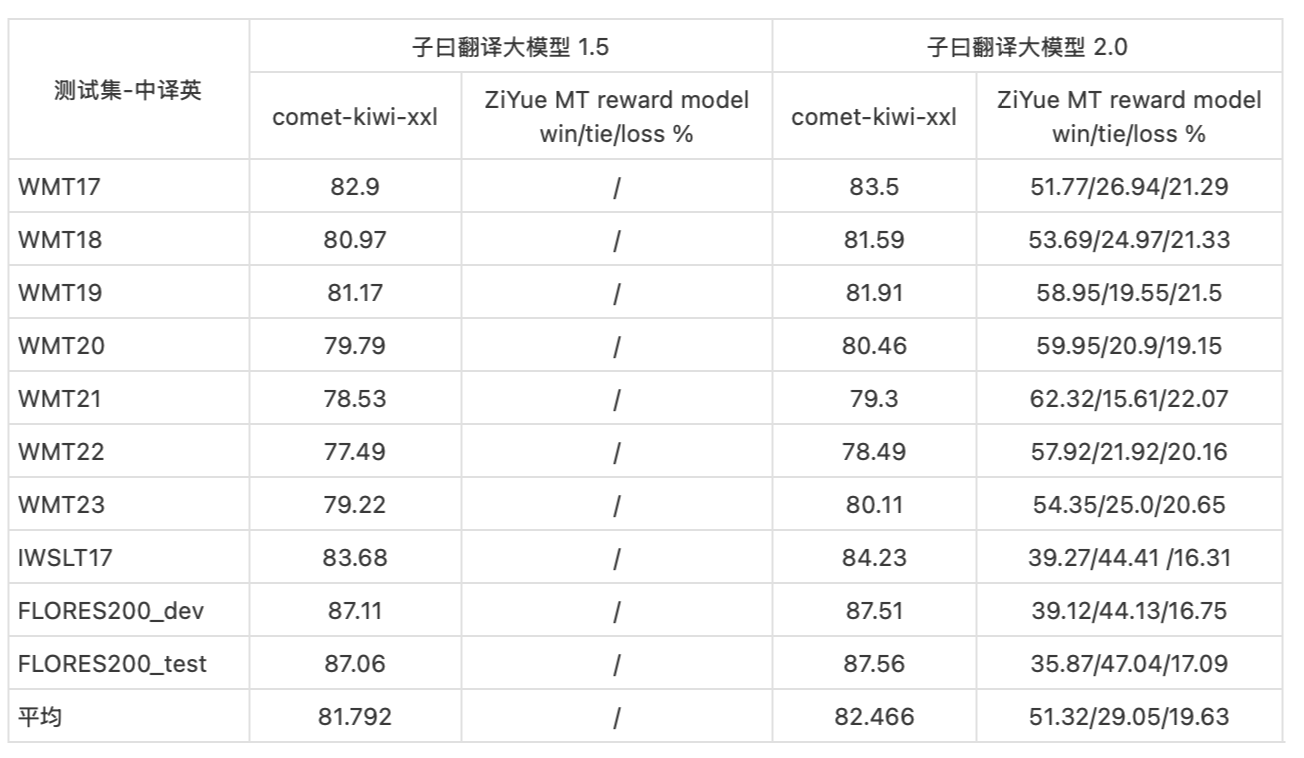
(采用测试集测试的结果)
为精准、客观地评估子曰翻译大模型2.0中英互译能力在行业中的表现,我们与多个国内外领先通用大模型及专业翻译器如DeepL Pro,进行了人工评估对比。
通过严谨的人工采集流程,我们构建了涵盖人文学科、商学、生活服务、医疗、科学等多个领域的数据样本集,并制定了全面精细的MQM评测方案,从专业性、准确性、语言惯例和风格等维度打分。
最终,五位资深翻译专家独立评估的结果汇总如下:
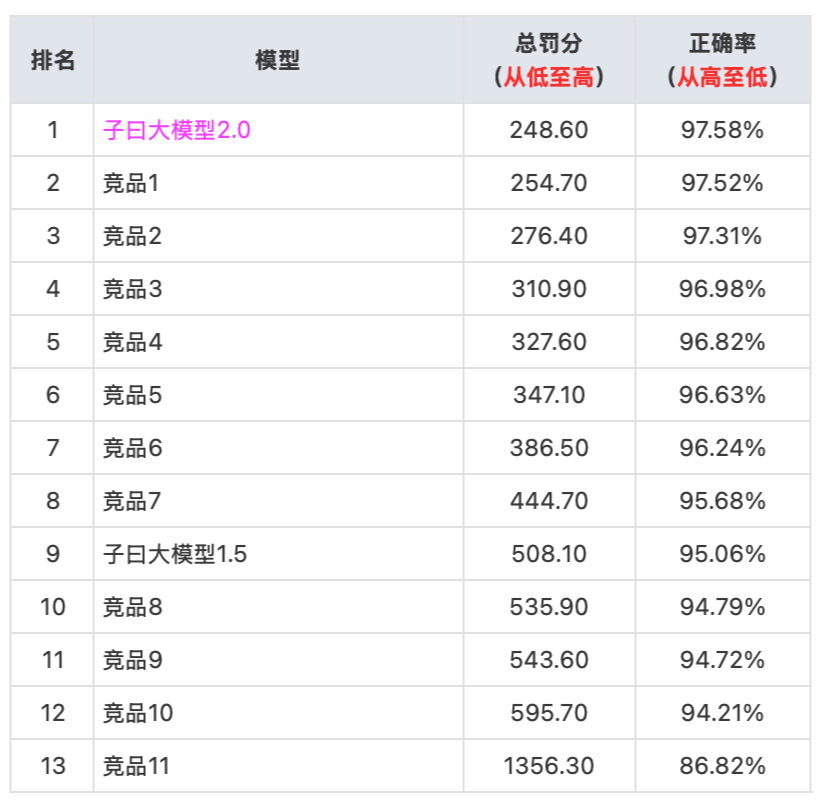
以上对比,凸显了子曰翻译大模型2.0在专有闭源模型中的竞争优势——在翻译准确性和流畅度上,远优于国内外通用大模型及专用翻译模型。
该测试不仅客观地呈现了我们的优势,也精准地指明了未来有待优化和改进的方向,坚定了我们在机器翻译领域持续推进改进与创新的决心。
但我们深知仍面临诸多挑战,在后续的工作中,我们将全力去推进支持更长文本输入、拓展更多模态的输入,以及增加更多语种的支持工作,我们期待在不久之后下一代子曰翻译大模型能跟大家见面。
在此欢迎各位持续关注更多有道AI技术的进展与突破,也诚邀大家前来体验“子曰翻译大模型 2.0”,期待您的反馈。
附:可体验入口
1、有道词典APP-首页入口
2、有道翻译桌面版-首页入口
3、有道翻译网页端-AI翻译入口

 微信
微信

 新浪微博
新浪微博

 有道云笔记
有道云笔记