摘要
计算机基础的同学估计对管道这个词都不陌生了,尤其是在Linux系统当中,管道操作符已经被广泛的使用,并给我们的变成带来了极大的便利。前端领域比较注明的脚手架“gulp”也是以其管道操作著称。
今天我们就来一步步抽丝剥茧,看看在前端领域的“管道数据流”要如何设计。
一、前言
有计算机基础的同学估计对管道这个词都不陌生了,尤其是在Linux系统当中,管道操作符已经被广泛的使用,并给我们的变成带来了极大的便利。管道操作通常分为单向管道和双向管道,当数据从上一节管道流向下一节管道时,我们的数据将会被这节管道进行一定的加工处理,处理完毕后送往下一节管道,依次类推,这样就可以对一些原始的数据在不断的管道流动中进行不断的加工,最后得到我们想要的目标数据。
在我们日常编程开发过程中,也可以尝试使用管道数据的概念,对我们的程序架构进行一定的优化,让我们程序的数据流动更加清晰明了,并可以让我们像是流水线一样,每个管道专门负责各自的工作对数据源进行一次粗加工,达到职责分明与程序解耦的目的。
二、程序设计
现在我们使用Typescript实现一个基础的管道类的设计,我们今天使用的管道是单向管道。
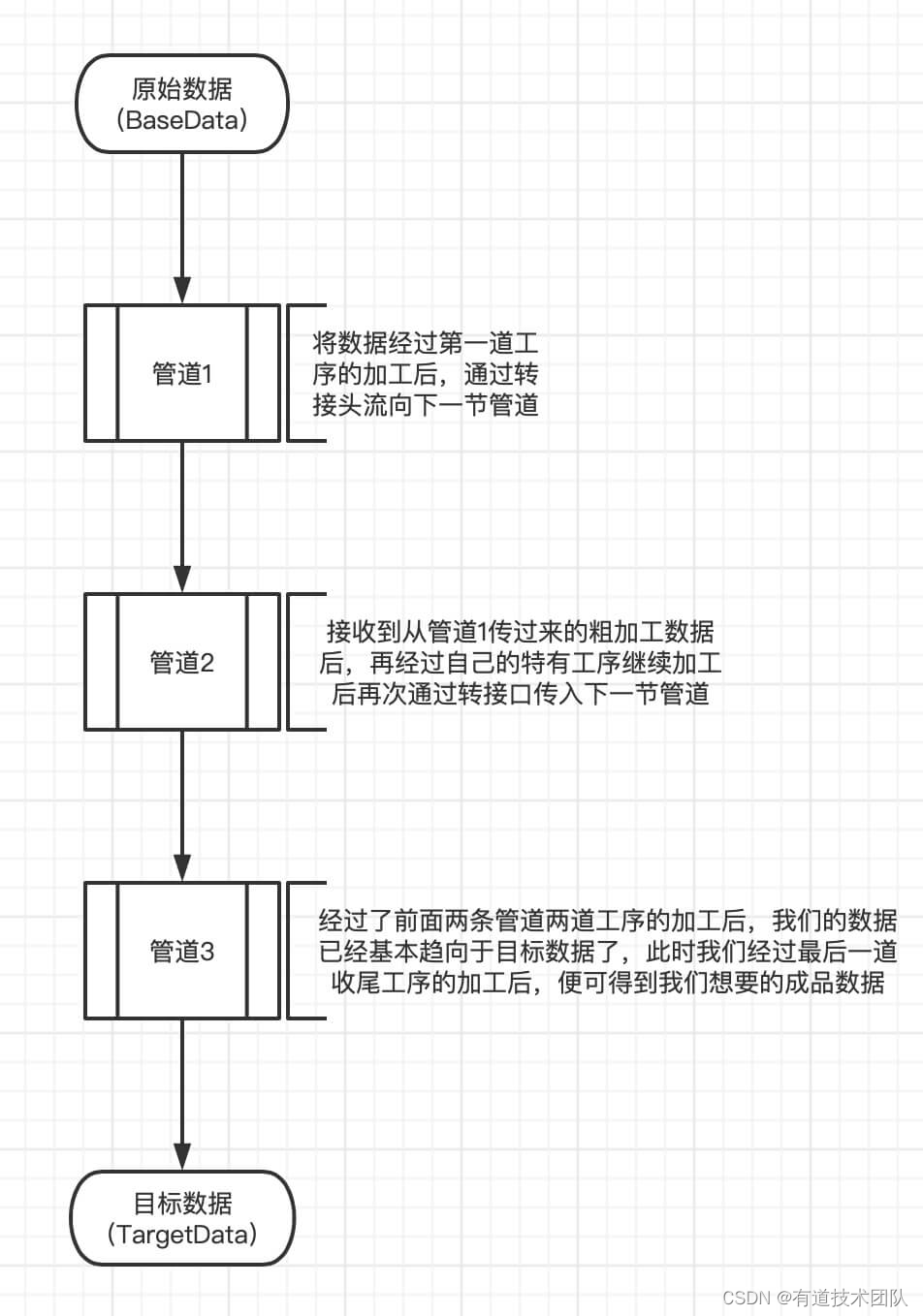
2.1 Pipe-转接头
顾名思义,转接头就是需要将不同的多节管道连接在一起成为一整条管道的连接口,通过这个连接头,我们可以控制数据的流向,让数据流向他真正该去的的地方。
首先,我们来设计一下我们的转接头的类型结构:
type Pipeline = {
/**
* 将多节管道链接起来
* e.g.
* const app = new BaseApp();
* app.pipe(new TestApp1()).pipe(new TestApp2()).pipe(new TestApp3()).pipe(new Output()).pipe(new End())
* @param _next
*/
pipe(_next: Pipeline): Pipeline;
}; 上述代码描述了一个支持管道数据的类需要有怎样的一个转接头,在程序设计中,我们的转接头其实就是一个函数,用于将多节管道相互链接。
从上面的代码大家可以看出,为了程序的高复用,我们选择对管道中传输的数据类型进行泛型化,这样,我们再具体实现某一个程序时,便可更加灵活的使用其中类型,例如:
// 时间类型的管道
type DatePipeline = Pipeline
// 数组类型的管道
type ArrayPipeLine = Pipeline
// 自定义数据类型的管道
type CustomPipeLine = Pipeline<{name: string, age: number}> 除此之外,我们这个函数的传入参数和返回值也是有讲究的,从上面的代码可以看出,我们接收一个管道类型的数据,又返回一个管道类型的数据。其中,参数中传入的便是下一节管道,这样,我们就把两节管道连接到了一起。之所以要返回一个管道类型的数据,是为了让我们使用时可以链式调用,更符合管道数据的设计理念,如:
const app = new AppWithPipleline();
app.pipe(new WorkerPipeline1())
.pipe(new WorkerPipeline2())
.pipe(new WorkerPipeline3())
.pipe(new WorkerPipeline4())也就是说,我们返回的,其实也是下一节管道的引用。
2.2 Push-水泵
有了转接头之后,我们还需要一个“水泵”将我们的数据源源不断地推送到不同的管道,最终到达目标点。
type Pipeline = {
/**
* 实现该方法可以将数据通过管道一层层传递下去
* @param data
*/
push(data: T[]): Promise;
/**
* 将多节管道链接起来
* e.g.
* const app = new BaseApp();
* app.pipe(new TestApp1()).pipe(new TestApp2()).pipe(new TestApp3()).pipe(new Output()).pipe(new End())
* @param _next
*/
pipe(_next: Pipeline): Pipeline;
}; 为了适应更多场景,我们设计这个水泵接受一个T[]类型的数组,在第一节管道当中,当我们拿到了初始的数据源时,我们就可以利用这个水泵(方法)将数据推送出去,让后面的每一个加工车间处理数据。
2.3 resolveData – 加工车间
当我们的数据被推送到某一节管道时,会有一个加工车间对推送过来的数据根据各自不同的工序进行粗加工。
注意:我们每一个加工车间应该尽可能保证职责分离,每个加工车间负责一部分的工作,对数据进行一次粗加工,而不是把所有的工作都放到一个加工车间当中,否则就失去了管道数据的意义。
type Pipeline = {
/**
* 实现该方法可以将数据通过管道一层层传递下去
* @param data
*/
push(data: T[]): Promise;
/**
* 将多节管道链接起来
* e.g.
* const app = new BaseApp();
* app.pipe(new TestApp1()).pipe(new TestApp2()).pipe(new TestApp3()).pipe(new Output()).pipe(new End())
* @param _next
*/
pipe(_next: Pipeline): Pipeline;
/**
* 用于接受从上一节管道传递下来的数据,可进行加工后传递到下一节管道
* @param data
*/
resolveData(data: T[]): T[] | Promise;
}; 加工车间依旧是接收一个T[]类型的数据数组,拿到这个数据后,按照各自的工序对数据进行加工处理,加工好之后,重新放回流水线的传送带上(返回值),送往下一节管道的加工车间继续加工。
三、具体实现
上面我们只是定义了一个管道应该有的最基本的行为,只有具备以上行为能力的类我们才认为它是一节合格的管道。那么,接下来,我们就来看看一个管道类需要如何实现。
3.1 基础管道模型类
class BaseApp implements Pipeline
{
constructor(data?: P[]) {
data && this.push(data);
}
/**
* 仅内部使用,下一节管道的引用
*/
protected next: Pipeline
| undefined;
/**
* 接受到数据后,使用 resolveData 处理获得新书局后,将新数据推送到下一节管道
* @param data
*/
async push(data: P[]): Promise {
data = await this.resolveData(data);
this.next?.push(data);
}
/**
* 链接管道
* 让 pipe 的返回值始终是下一节管道的引用,这样就可以链式调用
* @param _next
* @returns
*/
pipe(_next: Pipeline): Pipeline
{
this.next = _next;
return _next;
}
/**
* 数据处理,返回最新的数据对象
* @param data
* @returns
*/
resolveData(data: P[]): P[] | Promise {
return data;
}
}
我们定义了一个实现了Pipleline接口的基础类,用来描述所有管道的样子,我们所有的管道都需要继承到这个基础类。
在构造函数中,我们接受一个可选参,这个参数代表我们的初始数据源,只有第一节管道需要传入这个参数为整个管道注入初始数据,我们拿到这个初始数据后,会使用水泵(push)将这个数据推送出去。
3.2 管道统一数据对象
通常在程序实现时,我们会定义一个统一的数据对象作为管道中流动的数据,这样更好维护与管理。
type PipeLineData = {
datasource: {
userInfo: {
firstName: string;
lastName: string;
age: number,
}
}
}3.3 第一节管道
由于第一节管道之前没有任何管道了,我们想要让数据流动起来,就需要在第一节管道处使用水泵给予数据一个初始动能,让他可以流动起来,因此,第一节管道的实现会与其他管道略有不同。
export class PipelineWorker1 extends BaseApp {
constructor(data: T[]) {
super(data);
}
} 第一节管道主要的功能就是接受原始数据源,并使用水泵将数据发送出去,所以实现起来比较简单,只需要继承我们的基类BaseApp,并将初始数据源提交给基类,基类再用水泵将数据推送出去即可。
3.4 其他管道
其他管道每个管道都会有一个数据处理车间,用来处理流向当前管道的数据,因此我们还需要重写基类的resolveData方法。
export class PipelineWorker2 extends BaseApp {
constructor() {
super();
}
resolveData(data: PipeLineData[]): PipeLineData[] | Promise {
// 在这里我们可以对数据进行一些特定的处理
// 注意我们尽可能在传入的 data 上进行操作,保持引用
data.forEach(item => {
item.userInfo.name = ${item.userInfo.firstName} · ${item.userInfo.lastName}
});
// 最后,我们再调用基类的 resolveData 方法,把处理好的数据传进去,
// 这样就完成了一道工序的加工了
return super.resolveData(data);
}
}
export class PipelineWorker3 extends BaseApp {
constructor() {
super();
}
resolveData(data: PipeLineData[]): PipeLineData[] | Promise {
// 在这里我们可以对数据进行一些特定的处理
// 注意我们尽可能在传入的 data 上进行操作,保持引用
data.forEach(item => {
item.userInfo.age += 10;
});
// 最后,我们再调用基类的 resolveData 方法,把处理好的数据传进去,
// 这样就完成了一道工序的加工了
return super.resolveData(data);
}
}
export class Output extends BaseApp {
constructor() {
super();
}
resolveData(data: PipeLineData[]): PipeLineData[] | Promise {
// 在这里我们可以对数据进行一些特定的处理
// 注意我们尽可能在传入的 data 上进行操作,保持引用
console.log(data);
// 最后,我们再调用基类的 resolveData 方法,把处理好的数据传进去,
// 这样就完成了一道工序的加工了
return super.resolveData(data);
}
}
// 我们还可以利用管道组装灵活的特性开发出各种各样的插件,可随时插拔
export class Plugin1 extends BaseApp {
constructor() {
super();
}
resolveData(data: PipeLineData[]): PipeLineData[] | Promise {
// 在这里我们可以对数据进行一些特定的处理
// 注意我们尽可能在传入的 data 上进行操作,保持引用
console.log("这是一个插件");
// 最后,我们再调用基类的 resolveData 方法,把处理好的数据传进去,
// 这样就完成了一道工序的加工了
return super.resolveData(data);
}
} 3.5 组装管道
上面我们已经将每一节管道都准备好了,现在要把他们组装起来,投入使用了。
const datasource = {
userInfo: {
firstName: "kiner",
lastName: "tang",
age: 18
}
};
const app = new PipelineWorker1(datasource);
// 管道可以随意组合
app.pipe(new Output())
.pipe(new PipelineWorker2())
.pipe(new Output())
.pipe(new PipelineWorker3())
.pipe(new Output())
.pipe(new Plugin1());
四、结语
至此,我们就已经完成了一个管道架构的设计了。是不是觉得,使用了管道数据之后,我们的整个程序代码的数据流向更加清晰,每个模块之前的分工更加分明,模块与模块之前的项目配合更加灵活了呢?
使用管道设计,还能让我们可以额外扩充一个插件库,用户可以随意定制符合各个业务场景的插件,让我们的程序的扩展性变得极强。

 微信
微信

 新浪微博
新浪微博

 有道云笔记
有道云笔记