基于大语言模型技术的ChatGPT推出已经有4个月了,更多同类产品还在快速出现。比如,前天谷歌更新了Bard,将辅助编程能力支持的语言数量扩展到20种。
然而,对大模型技术的重要性也出现了质疑,前段时间,吴军老师就评价ChatGPT不算新技术革命,带不来什么新的机会,他认为大模型仍然存在很多限制,不像大家追捧的那样有吸引力。这篇文章发布后,网上也出现了多篇反驳文章。我不太关注这些争论,但我认为有一个问题没有被充分讨论,那就是大模型带来的新能力中,哪些是最为关键的,最有可能带来长期影响的。
我认为,与之前众多的自然语言处理技术相比,大语言模型至少具有三项根本性新能力,这些新能力在学术界已经被广泛讨论,甚至被视为常识,但是在产业界和产品团队中却缺乏足够的关注。实际上,这些大模型技术的特点已经改变了我们对业务和产品规划的思考方式,也会改变很多产品的经济模型。因此,产品经理和业务负责人需要更多地关注和深入思考这些新能力的应用场景。
能力一:涌现能力(emergent abilities)
涌现能力指的是在小型模型中并不存在,但在大模型中“突然出现”的能力,其中包括常识推理、问答、翻译、数学、摘要等(详见下图)。如果仅依靠小型模型的能力做线性外推,往往无法预测出涌现能力的出现和其强度。OpenAI的首席技术官Ilya Sutskever在接受采访时反复强调,尽管表面上看来,语言模型只是在预测下一个词元(token),但当模型足够大,transformer技术的建模能力足够强时,基于内部表示的推理能力就会出现。因此,模型会呈现出与规模较小时完全不同的行为,涌现全新的能力。
涌现能力之所以重要,不仅因为它们是大模型出现后才有的新能力,而且由大模型涌现出来的多数是非常重要的能力。例如,常识推理能力一直是AI领域的重大难题,而大模型的出现使得常识推理取得了重大进展。此外,大模型还有机会进一步获得更多能力。例如,一旦“推理”能力涌现,“思维链提示”(Chain of Thought Prompting)策略就可以用来解决多步推理的难题。因此,涌现能力的出现,是大模型带来的一项根本性变化。
能力二:作为基座模型支持多元应用的能力
在2021年,斯坦福大学等多所高校的研究人员提出了基座模型(foundation model)的概念,这更清晰地描述了之前学界所称的预训练模型的作用。这是一种全新的AI技术范式,借助于海量无标注数据的训练,获得可以适用于大量下游任务的大模型(单模态或者多模态)。这样,多个应用可以只依赖于一个或少数几个大模型进行统一建设。
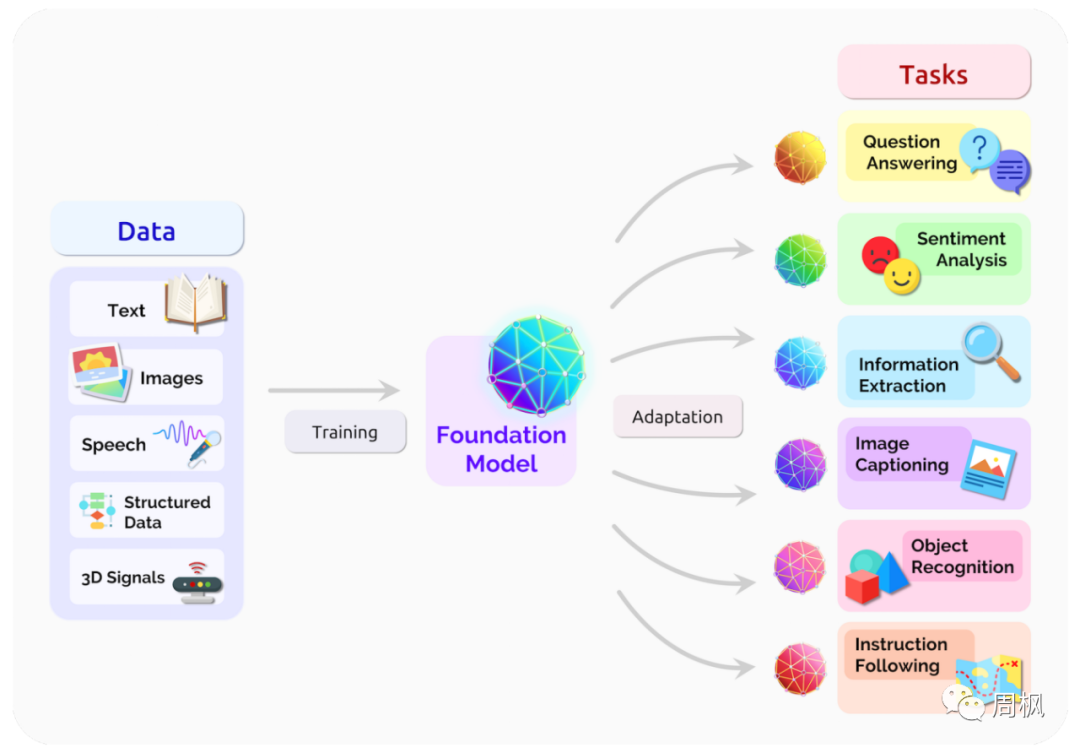
上图展示了基座模型的结构,基座模型集中化了多模态数据,并且可以适配多元化的下游任务。
大语言模型是这个新模式的典型例子,使用统一的大模型可以极大地提高研发效率,相比于分散的模型开发方式,这是一项本质上的进步。大型模型不仅可以缩短每个具体应用的开发周期,减少所需人力投入,也可以基于大模型的推理、常识和写作能力,获得更好的应用效果。因此,大模型可以成为AI应用开发的大一统基座模型,这是一个一举多得、全新的范式,值得大力推广。
能力三:支持对话作为统一入口的能力
让大语言模型真正火爆的契机,是基于对话聊天的ChatGPT。事实上,业界很早就发现了用户对于对话交互的特殊偏好,陆奇在微软期间2016年就推进“对话即平台(conversation as a platform)”的战略。此外,苹果Siri、亚马逊Echo等基于语音对话的产品也非常受欢迎,反映出互联网用户对于聊天和对话这种交互模式的偏好。虽然之前的聊天机器人存在各种问题,但大型语言模型的出现再次让聊天机器人这种交互模式可以重新想像。用户愈发期待像钢铁侠中“贾维斯”一样的人工智能,无所不能、无所不知。这引发我们对于智能体(Agent)类型应用前景的思考,Auto-GPT、微软Jarvis等项目已经出现并受到关注,相信未来会涌现出很多类似的以对话形态让助手完成各种具体工作的项目。

图为微软最新项目Jarvis的工作流程,Jarvis将通过任务规划、模型选择、任务执行、生成响应四个步骤,结合HuggingFace上的众多模型,完成多模态的复杂AI任务。
随着大型语言模型技术越来越受欢迎,我们可以期待它带来更多的惊喜,特别是考虑到上面讨论的这些大型模型带来的关键新能力,周明等人所预测的语言智能黄金十年(2020-2030)很可能会成为现实,这正是一个令人兴奋的时代。

 微信
微信

 新浪微博
新浪微博

 有道云笔记
有道云笔记