作者/ 韩虹莹
编辑/ Ein
从人和信息的博弈谈推荐系统缘起
首先谈谈我理解的推荐系统。
如果说推荐系统的定义是什么,每本书每篇文章说的都不太一样,协同过滤1992年就已经有了,三十年里无数大佬分析了个性化推荐的缘起和意义,世界已经不需要多一个人的见解。但是,当所有人都说一件事情是正确的时候,我们也要想清楚它为什么是正确的。
如果你问我推荐系统是什么,我会告诉你,是信息到人的精准分发。那么为什么在这个时代推荐系统才应运而生?古人不会需要信息精准分发,车马信息都很慢,古人学富五车不过现在一个书包的信息量;唯有现在人才需要信息精准分发,信息太多时间太少,乱花渐欲迷人眼,所以我们需要一个智能的系统,帮助你过来过滤信息,所以推荐系统是人和信息的桥梁。
当然,正如罗马不是一天建成的一样,在互联网上搭个桥也是要演进的,最开始是个小木桥——门户网站,用分类导航分发了信息;后来演化到了石板桥——搜索引擎,人可以更精准的找信息;逐步的信息太多了,要变成信息找人,在这个过程中,无论是信息的消费者,还是信息的生产者,都遇到了不曾预见的困难,信息消费者找不到信息了,信息生产者无法让自己的信息展现在消费者眼前,有痛点就有需求,有需求就有产品,于是推荐系统作为一个产品,恰到好处又必然的到来。凯文凯利在《必然》里,把这个趋势称为“过滤”:
进行过滤是必然的,因为我们在不停地制造新东西。而在我们将要制造的新东西中,首要的一点就是创造新的方式来过滤信息和个性化定制,以突显我们之间的差异。
人如何和信息相处,推荐系统既不是起点,恐怕也不会是终局,但它已经是当前人们对于处理信息所能做的最好的实践了。
推荐系统要如何满足需求
推荐系统应该单独作为一个产品来看,他是一个什么产品呢?作为一个加工信息的产品,它一定要满足信息供需两端的需求,才有价值。
所以作为一个推荐系统,要把自己定义在一个中间方的位置,可以说 C 端用户和产品经理都是你的用户,两端的需求都需要被满足,所以既需要你想技术方案,还需要你去想,你怎么更好的满足两端的需求,用户只需要你精准的帮他找到信息。而对于产品方,需要挖掘想通过推荐系统获得什么。
对于用户端(信息需求端),最迫切的需求是如何帮我精准的找到我需要的信息。
对于公司端(信息供应端),是为了满足一些商业化的需求,比如吸引用户,增强用户黏性,提高用户转化率,比如资讯平台,短视频平台,信息流平台希望提升用户活跃度,延长用户停留时间,电商平台希望提高用户购买转化率。
推荐系统常规架构
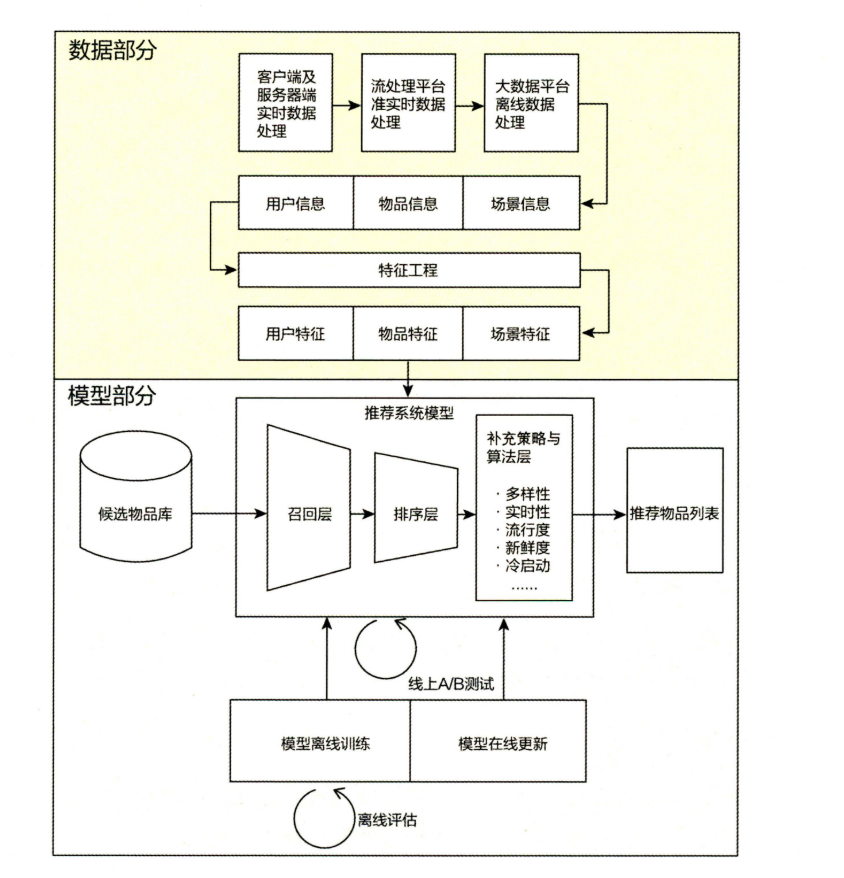
从上图来看,一个完整的推荐系统包括数据部分和模型部分,数据部分主要依赖大数据离线或在线处理平台,主要完成的工作包括数据的收集和 ETL 处理,生成推荐模型所需要的特征数据。
推荐系统模型部分是主体,这部分要在提供推荐模型服务之前,完成模型的训练,然后对输入数据进行处理,通过不同的召回或排序策略,生成最后的输出结果。一个常规的工业级推荐系统,在模型部分主要包括召回层,过滤层,排序层,也可根据业务需要判断是否需要补充策略与算法层。
1. “召回层” 一般利用高效的召回规则、算法或简单的模型,快速从海量的候选集中召回用户可能感兴趣的物品。
2. “过滤层” 一般根据特定场景业务需求,对召回的数据进行过滤。
3. “排序层” 利用排序模型对初筛的候选集进行精排序。
4. “补充策略与算法层” 也被称为”再排序层”,可以在将推荐列表返回用户之前,为兼顾结果的”多样性” “流行度” “新鲜度”等指标,结合一些补充的策 略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表。
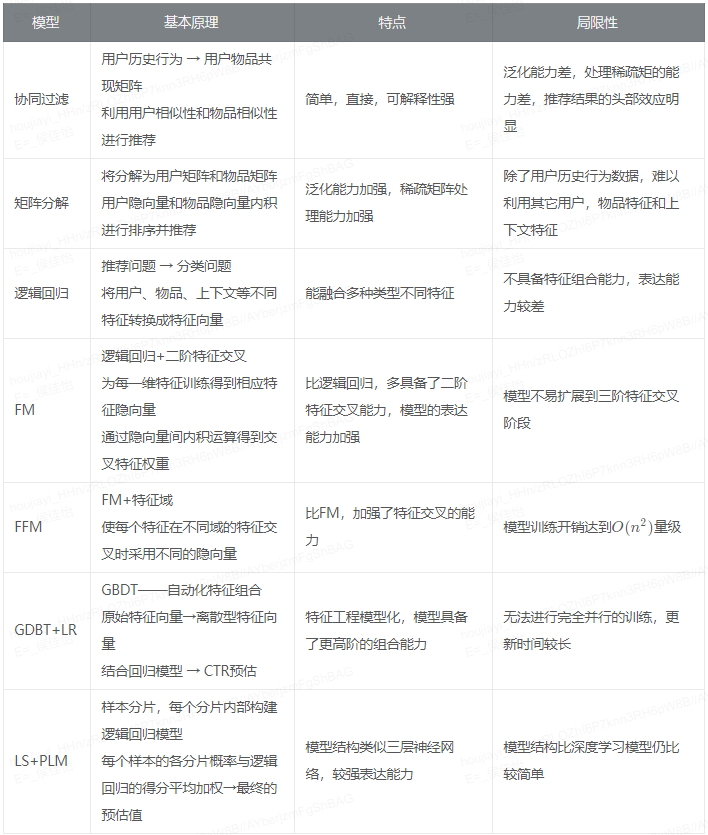
推荐系统常见模型概述与比较
先来一个推荐算法发展的时间线
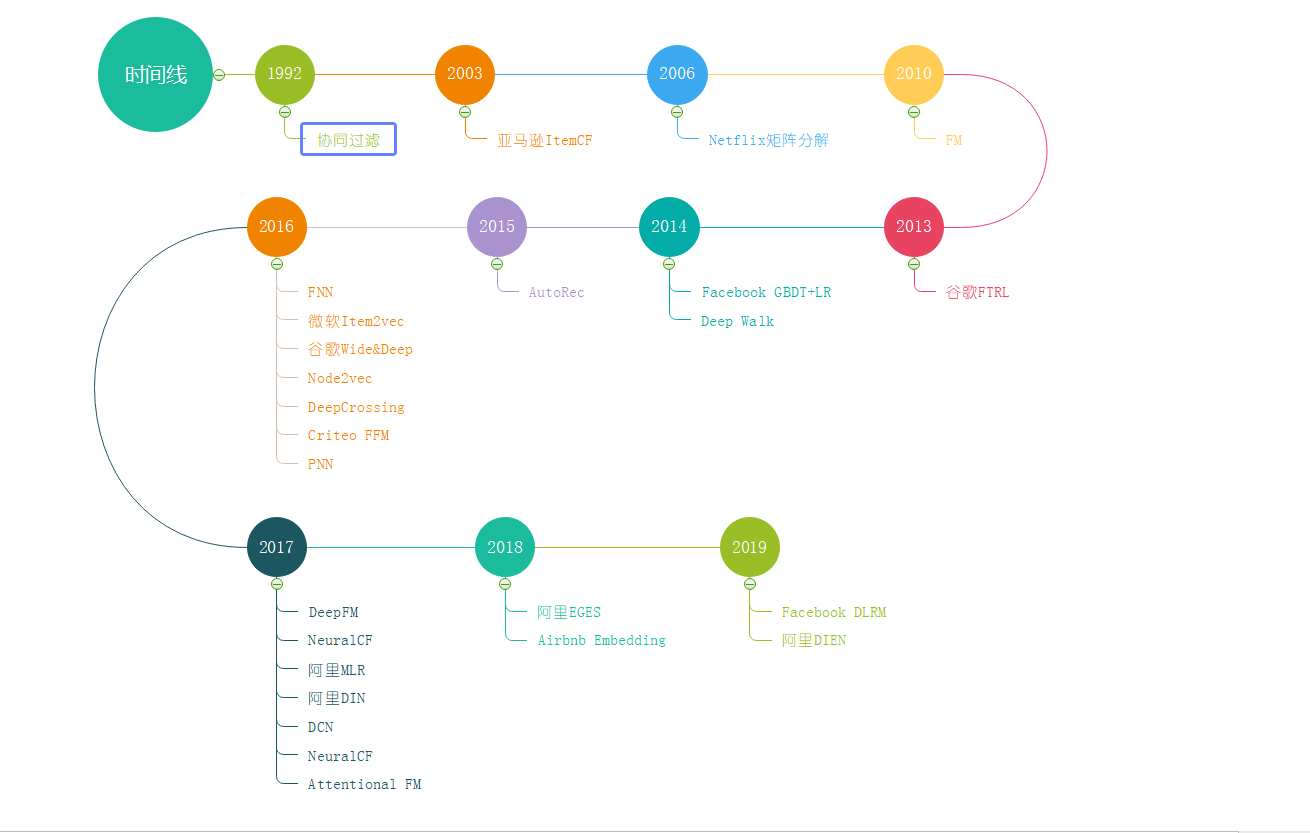
可以从图中看出,2016年是推荐系统从传统机器学习模型到深度学习模型的转折点,这一年微软的 Deep Crossing ,谷歌的 Wide&Deep ,以及 FNN 、 PNN 等一大批 优秀的深度学习推荐模型相继推出,继而逐渐成为推荐系统的主流。但传统推荐模型仍然要被重视,第一它们是深度学习的基础,很多东西都是一脉相承的,矩阵分解的隐向量思想在Embedding中继续发展,FM中的核心思想——特征交叉也在深度学习中继续使用,逻辑回归可以看做神经元的另一种表现形式。第二这些算法的硬件要求低,结果可解释性强,训练容易,仍是大量场景所适用的。
机器学习推荐模型演化过程
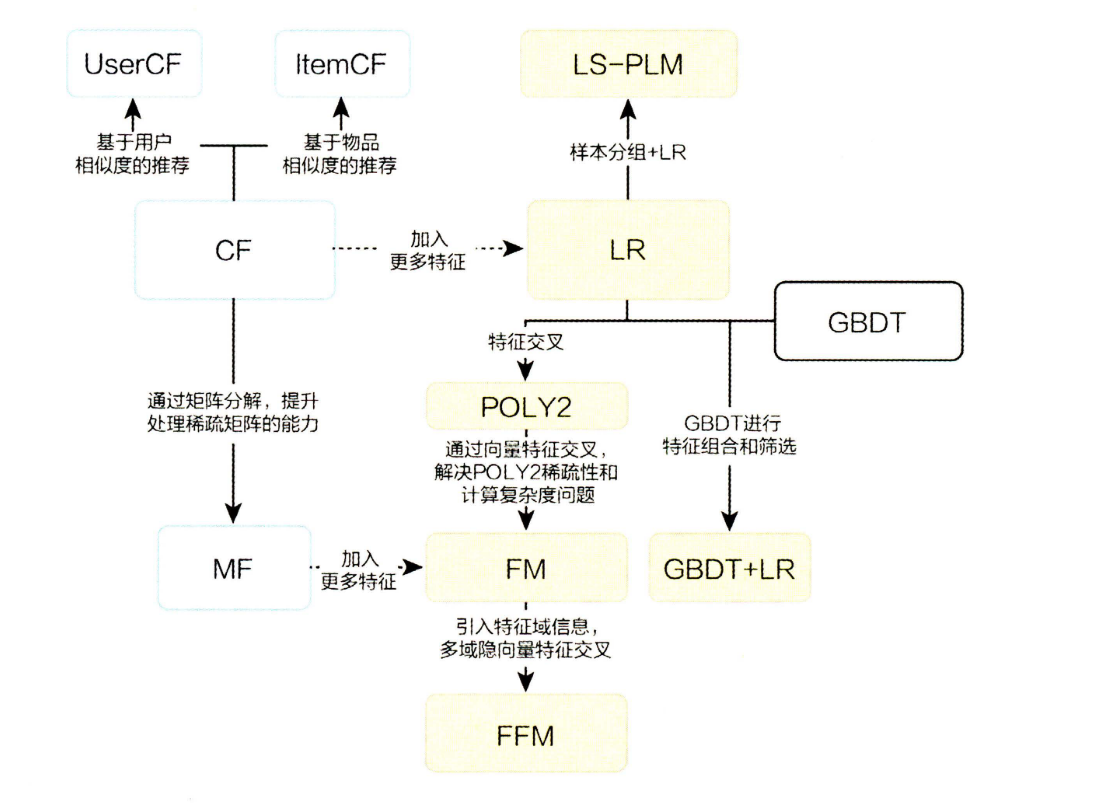
可以从图中看出,2016年是推荐系统从传统机器学习模型到深度学习模型的转折点,这一年微软的 Deep Crossing ,谷歌的 Wide&Deep ,以及 FNN 、 PNN 等一大批 优秀的深度学习推荐模型相继推出,继而逐渐成为推荐系统的主流。但传统推荐模型仍然要被重视,第一它们是深度学习的基础,很多东西都是一脉相承的,矩阵分解的隐向量思想在Embedding中继续发展,FM中的核心思想——特征交叉也在深度学习中继续使用,逻辑回归可以看做神经元的另一种表现形式。第二这些算法的硬件要求低,结果可解释性强,训练容易,仍是大量场景所适用的。
协同过滤
协同过滤是推荐系统领域应用最广泛的模型了,而且大家一说到推荐系统,就会直接关联到协同过滤,而且是基于用户的协同过滤 or 基于物品的协同过滤,其实从某种程度上理解,矩阵分解也是协同过滤的一种,基于用户,商品的协同过滤属于基于近邻的协同过滤,从更大一点的范围来说,大多数机器学习和分类算法可以理解为协同过滤的一个分支,协同过滤可以看做是分类问题的泛化,正是因为这个原因,适用于分类的许多模型也可以通过泛化应用于协同过滤。
本节主要针对的,还是广泛意义上理解的,基于近邻的协同过滤,这类协同过滤,其实就是基于用户-用户,物品-物品的相似度计算。
基于用户协同过滤
当用户需要个性化推荐时,可以先找到与他相似其他用户(通过兴趣、爱好或行为习惯等,然后把那些用户喜欢的并且自己不知道的物品推荐给用户。
步骤: – 准备用户向量,在该矩阵中,理论上每个用户得到一个向量 – 向量维度是物品个数,向量是稀疏的,向量取值可以是简单的0或1 – 用每个用户向量,两两计算用户之间相似度,设定一个相似度阈值,为每个用户保留与其最相似的用户 – 为每个用户产生推荐结果
基于物品协同过滤
基于物品的协同过滤算法简称,其简单应用情景是:当一个用户需要个性化推荐时,例如由于他之前购买过金庸的《射雕英雄传》这本书,所以会给他推荐《神雕侠侶》,因为其他用户很多都同时购买了这两本书。
步骤: – 构建用户物品的关系矩阵,可以是购买行为,或购买后的评价,购买次数等 – 两两计算物品相似度,得到物品相似度矩阵 – 产生推荐结果,典型的两种形式:①为某个物品推荐相关物品;②个人首页的“猜你喜欢”
计算相似度的方式有如下几种:
①余弦相似度,余弦相似度( Cosine Similarity )衡量了用户向量t和用户向量j之间的向量夹角大小。 显然,夹角越小,证明余弦相似 度越大,两个用户越相似。
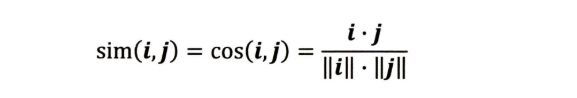
②皮尔逊相关系数,相比余弦相似度,皮尔逊相关系数通过使用用户平均分对各独立评分进行修正,减小了用户评分偏置的影响 。
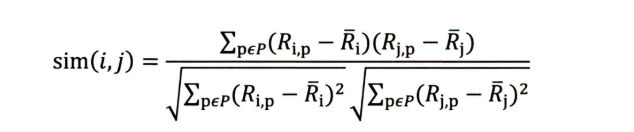
矩阵分解
关于矩阵分解,一种讲法把它划归为协同过滤,认为他是基于模型的协同过滤,另一种则认为他是协同过滤的进化,其实这个到影响不大,矩阵分解是在协同过滤的基础上,增加了隐向量的概念。
矩阵分解可以解决一些邻域模型无法解决的问题:①物品之间存在关联性,信息量不随向量维度线性增加;②矩阵元素稀疏,计算结果不稳定,增减一个向量,结果差异很大。
矩阵分解把User矩阵和Item矩阵作为未知量,用它们表示出每个用户对每个item的预测评分,然后通过最小化预测评分跟实际评分的差异,学习出User矩阵和Item矩阵。也就是说,图2中只有等号左边的矩阵是已知的,等号右边的User矩阵和Item矩阵都是未知量,由矩阵分解通过最小化预测评分跟实际评分的差异学出来的。
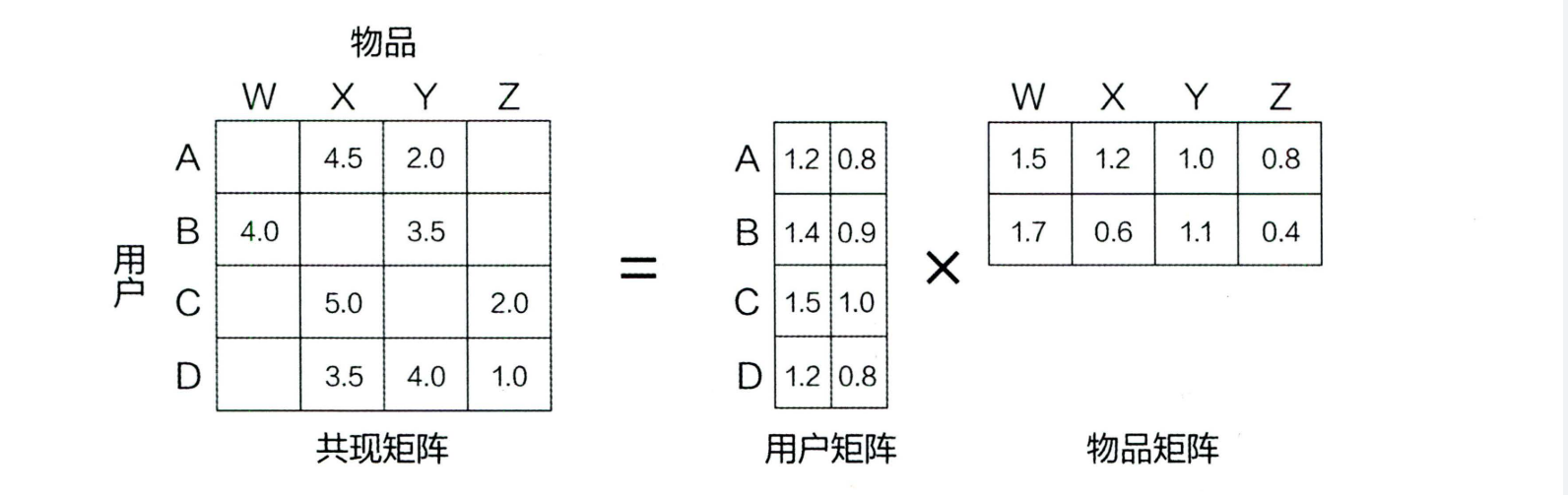
矩阵分解用到的用户行为数据分为显式数据和隐式数据两种。显式数据是指用户对item的显式打分,比如用户对电影、商品的评分,通常有5分制和10分制。隐式数据是指用户对item的浏览、点击、购买、收藏、点赞、评论、分享等数据,其特点是用户没有显式地给item打分,用户对item的感兴趣程度都体现在他对item的浏览、点击、购买、收藏、点赞、评论、分享等行为的强度上。我们当前主要是隐式数据。
目标函数通过最小化预测评分和实际评分ruirui 之间的残差平方和,来学习所有用户向量和物品向量
显示矩阵目标函数

隐式矩阵目标函数

求解方法:矩阵分解的方法也不止一种,有奇异值分解,梯度下降,交替最小二乘,这里简单列举一个交替最小二乘的例子。
ALS(交替最小二乘法):先固定X 优化Y ,然后固定Y 优化X ,这个过程不断重复,直到X 和Y 收敛为止。
这里举一个,显式矩阵中固定Y优化X的例子,另外固定X优化Y:
- 目标函数被拆解为多个独立目标函数,每个用户对应一个目标函数,用户u的目标函数为:

- 该目标函数转换为矩阵形式。
- 对目标函数J关于Xu求梯度,并令梯度为零。
逻辑回归→POLY2→FM→FFM
首先逻辑回归的想法很巧妙,把推荐系统的推荐问题看做了一个分类问题,为什么可以这样说呢?
逻辑回归可以通过sigmoid 函数,将输入特征向量x=(x1,x2……xn)x=(x1,x2……xn),映射到(0,1)区间,如下图所示:

逻辑回归有着很多优势: – 数学含义上的支撑,逻辑回归的假设是因变量y服从Bernoulli分布,非常符合我们对于CTR模型的认识,相比之下线性回归模型假设y服从高斯分布,这与我们所理解的CTR预估模型(二分类问题)并不一致。 – 可解释性强,逻辑回归的简单数学形式也非常符合人类对 预估过程的直觉认知 – 工程化简单,具有易于并行化,训练简单,训练开销小的特点
但也有一些缺点: – 表达能力不强,无法进行特征交叉、特征筛选等操作,所以会造成一些信息的损失
正是由于这个原因,后面出现了POLY2模型,FM模型,FFM模型,接下来我一起说明:
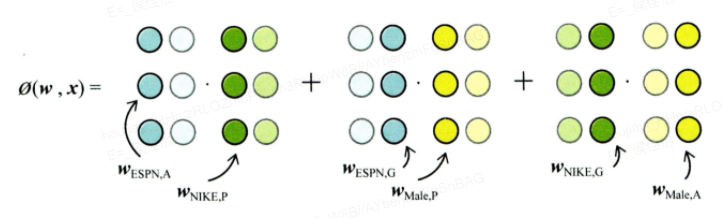
POLY2模型——特征的“暴力”组合
该模型对所有特征进行了两两交叉(特征 Xj1 和 Xjz),并对所有的 特征组合赋予权重 Wh(j1,j2),本质上还是一个线性模型:
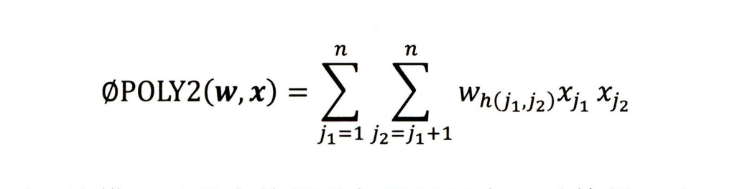
FM——隐向量的特征交叉
FM与POLY2的主要区别是用两个向量的内积(Wj1,Wj2) 取代了单一的权重系数Wh(j1,j2)。
- FM为每个特征学习了一个隐权重向量,特征交叉时,使用两个特征隐向量的内积作为交叉特征的权重。
- 引入隐向量的做法,与矩阵分解的思想异曲同工,是从单纯用户-物品扩展到了所有特征上。
- 把POLY2模型 n^2的权重参数减少到了nk。
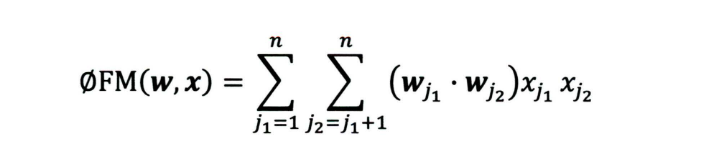
FM这样做的优势在于,隐向量的引人使 FM 能更好地解决数据稀疏性的问题,泛化能力大大提高。在工程方面, FM 同样可以用梯度下降法进行学习,使其不失实时性和灵活性 。
FFM——特征域

FFM 与 FM 的区别在于隐向量由原来的 Wj1 变成了 Wj1,f2,这意味着每个特征对应的不是唯一一个隐向量,而是一组隐向量,当特征 xj1 与特征 xj2 进行交叉时,xj1 会从 xj1 这一组隐向量中挑出与特征xj2的域f2对应的隐向量 Wj1,f2 进行交叉,同理, xj2 也会用与 xj1的域f1对应的隐向量进行交叉。
模型演化的形象化表示
POLY2模型

FM模型

FFM模型
传统机器学习算法比较
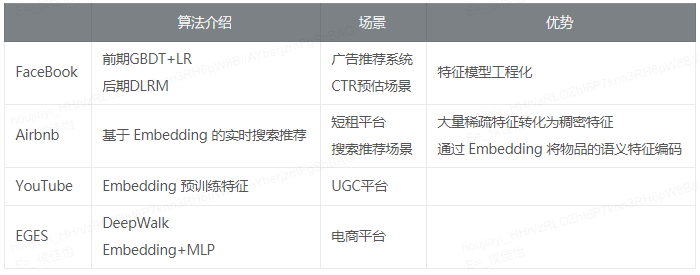
大厂如何玩转推荐系统
大厂实践比较
这里选取了几个比较典型的推荐系统实现,他们分别属于几种推荐系统的典型场景
深度学习算法比较
针对几个大厂部分采用了一些深度学习的模型,这里也调研对比了深度学习模型的特点和优劣势 
云课堂的个性化推荐
特征工程
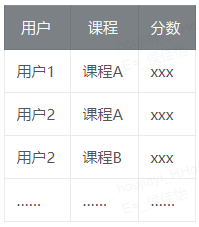
主要选用了用户行为数据,用户行为数据在推荐系统中有显性反馈行为和隐性反馈行为两种,在云课堂场景下,用户的评分属于显性行为,用户的购课,学习,做笔记等都属于隐性行为。对于这些行为,我们根据业务重要程度,都给出了初始分数,生成了用户-课程的初始评分矩阵
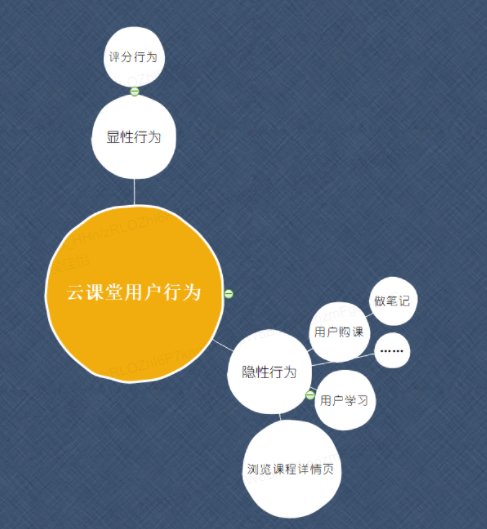
评分矩阵简单表示如下:
算法选型
在个性化推荐系统搭建初期,由于我们是从0到1开始构建,所以并没有选择在初期选择复杂的深度学习算法,以及构建丰富的用户画像,希望在初期快速构建一个MVP版本上线,后续逐步反思优化迭代
所以在算法选型上,我们从下面三种方案中进行评估选择
- 基于标签匹配
- 基于用户/行为的协同过滤
- 基于矩阵分解的协同过滤
那么我们是如何进行取舍的?
关于方案一,如果希望方案一取得较好的效果,关键点在于依赖标签体系的建设,只有标签体系足够完善,也就是说,推荐结果的好坏,是可预计的,强依赖于标签体系的建设的。
关于方案二,它的缺点在于处理稀疏矩阵的能力较弱,而云课堂中用户的学习行为并不能算是高频行为,同时头部效应明显,而我们希望的是通过个性化推荐系统,挖掘更多隐含的可能性,保留更多平台上更多平时没机会暴露的课程,显然基于近邻方式的协同过滤,不是一个很合适的选择。而基于矩阵分解的方法可以一定程度上增强稀疏矩阵的处理能力,同时引入隐向量,可以从用户行为中挖掘更多的可能性。
我们选用了基于ALS(交替最小二乘法)的矩阵分解模型作为第一个实践的算法,采用的是Spark MLlib提供的API。
在ALS模型的构建过程中,需要调整如下几个参数以取得最好的效果 
对于上面几个参数,分别调整了几次参数,以MSE 和 RMSE 作为评价指标
均方误差( Mean Square Error , MSE)和均方根误差( Root Mean Square Error , RMSE) 经常被用来衡量回归模型的好坏。一般情况下, RMSE 能够很好地反映回归模型预测值与真实值的偏离程度 。 但在实际应用时,如果存在个别偏离程度非常大的离群点 , 那么即使离群点数量 非常少 , 也会让这两个指标变得很差 。

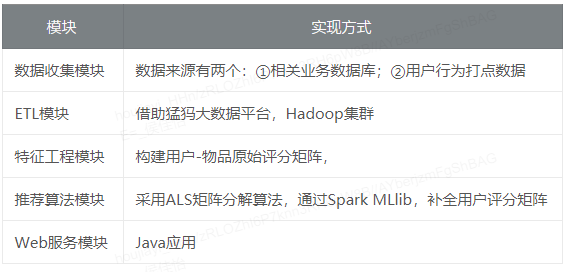
工程落地
一个可以落地的推荐系统,数据收集模块,ETL模块,特征工程模块,推荐算法模块,Web服务模块模块是必不可少的,首先来一个整体架构图:
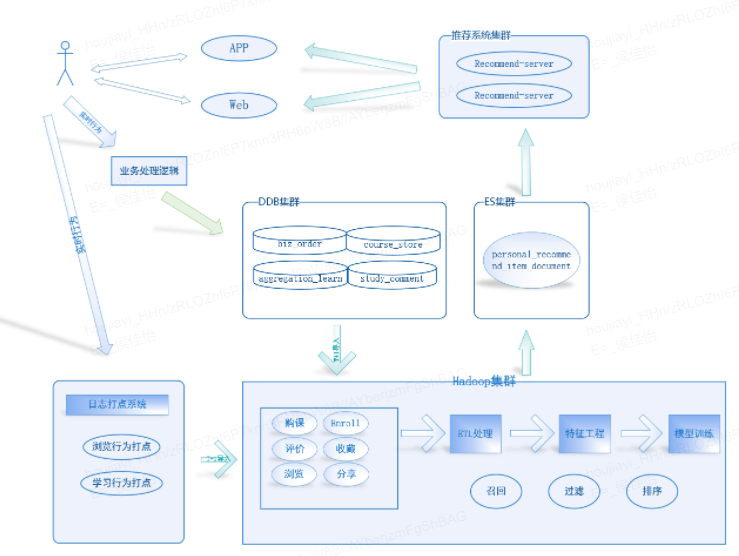
接下来简单对几个模块的实现进行说明:
参考文献
1.《深度学习推荐系统》王喆
2.《推荐系统 原理与实践》 Charu C. Aggarwal
-END-

 微信
微信

 新浪微博
新浪微博

 有道云笔记
有道云笔记