

1.概述
本系列文章共2篇。在上一篇《原理篇》中,我们看到了异步非阻塞模型,它能够有效降低线程IO状态的耗时,提升资源利用率和系统吞吐量。异步API可以表现为listener或Promise形式;其中Promise API提供了更强的灵活性,支持同步返回和异步回调,也允许注册任意数目的回调。
在本文《应用篇》中,我们将进一步探索异步模式和Promise的应用:
第2章:Promise与线程池。 在异步执行耗时请求时,ExecutorService+Future是一个备选方案;但是相比于Future,Promise支持纯异步获取响应数据,能够消除更多阻塞。
第3章:异常处理。 Java程序并不总能成功执行请求,有时会遇到网络问题等不可抗力。对于无法避免的异常情况,异步API必须提供异常处理机制,以提升程序的容错性。
第4章:请求调度。 Java程序有时需要提交多条请求,这些请求之间可能存在一定的关联关系,包括顺序执行、并行执行、批量执行。异步API需要对这些约束提供支持。
本文不限定Promise的具体实现,读者在生产环境可以选择一个Promise工具类(如netty DefaultPromise[A]、jdk CompletableFuture[B]等);此外,由于Promise的原理并不复杂,读者也可以自行实现所需功能。
2.Promise与线程池
Java程序有时需要执行耗时的IO操作,如数据库访问;在此期间,相比于纯内存计算,IO操作的持续时间明显更长。为了减少IO阻塞、提高资源利用率,我们应该使用异步模型,将请求提交到其他线程中执行,从而连续提交多条请求,而不必等待之前的请求返回。
本章对几种IO模型进行对比(见2.1节),考察调用者线程的阻塞情况。其中,Promise支持纯异步的请求提交及响应数据处理,能够最大程度地消除不必要的阻塞。在实际项目中,如果底层API不支持纯异步,那么我们也可以进行适当重构,使其和Promise兼容(见2.2节)。
2.1 对比:同步、Future、Promise
本节对几种 IO 模型进行对比,包括同步 IO、基于线程池(ExecutorService)的异步 IO、基于 Promise 的异步IO,考察调用者线程的阻塞情况。假设我们要执行数据库访问请求。由于需要跨越网络,单条请求需要进行耗时的 IO操作,才能最终收到响应数据;但是请求之间没有约束,允许随时提交新的请求,而不需要收到之前的响应数据。
首先我们来看看几种模型的样例代码:
1.同步IO。db.writeSync()方法是同步阻塞的。函数阻塞,直至收到响应数据。因此,调用者一次只能提交一个请求,必须等待该请求返回,才能再提交下一个请求。

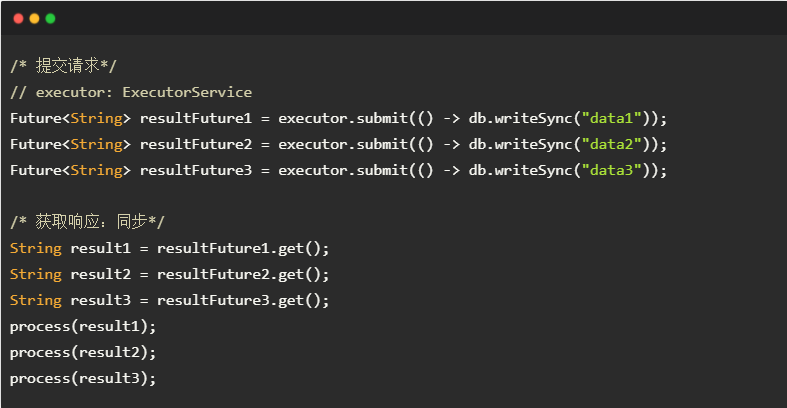
2.基于线程池(ExecutorService)的异步IO。db.writeSync()方法不变;但是将其提交到线程池中来执行,使得调用者线程不会阻塞,从而可以连续提交多条请求data1-3。
提交请求后,线程池返回 Future 对象,调用者调用 Future.get() 以获取响应数据。Future.get() 方法却是阻塞的,因此调用者在获得响应数据之前无法再提交后续请求。
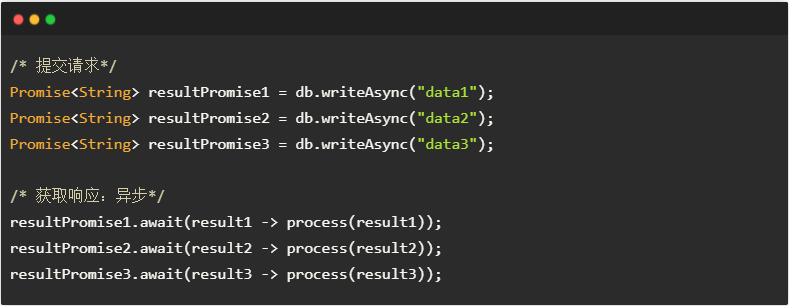
3.基于Promise的异步IO。db.writeAsync()方法是纯异步的,提交请求后返回 Promise 对象;调用者调用Promise.await()注册回调,当收到响应数据后触发回调。
在《原理篇》中,我们看到了 Promise API 可以基于线程池或响应式模型实现;不论哪种方式,回调函数可以在接收响应的线程中执行,而不需要调用者线程阻塞地等待响应数据。
接下来我们看看以上几种模型中,调用者线程状态随时间变化的过程,如图2-1所示。
a.同步 IO。调用者一次只能提交一个请求,在收到响应之前不能提交下一个请求。
b.基于线程池的异步 IO。同一组请求(请求1-3,以及请求4-6)可以连续提交,而不需要等待前一条请求返回。然而,一旦调用者使用 Future.get() 获取响应数据(result1-3),就会阻塞而无法再提交下一组请求(请求4-6),直至实际收到响应数据。
c.基于 Promise 的异步 IO。 调用者随时可以提交请求,并向Promise注册对响应数据的回调函数;稍后接收线程向Promise通知响应数据,以触发回调函数。上述过程中,调用者线程不需要等待响应数据,始终不会阻塞。
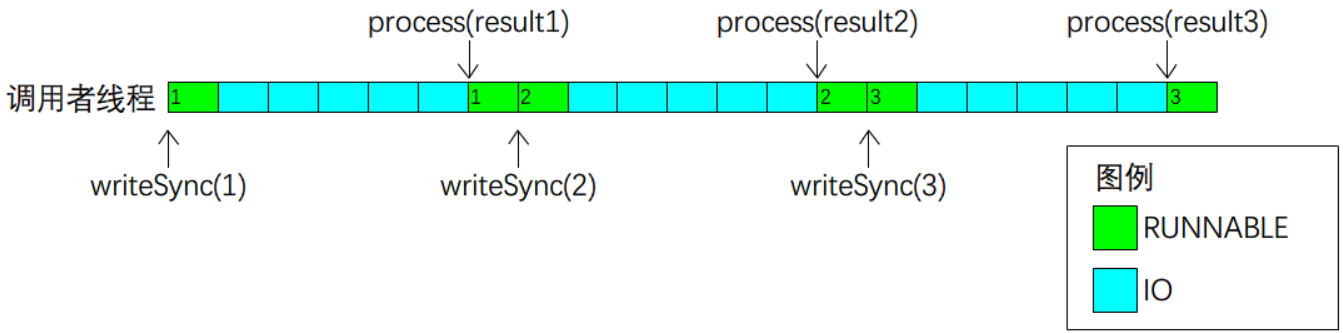
图2-1a 线程时间线:同步IO
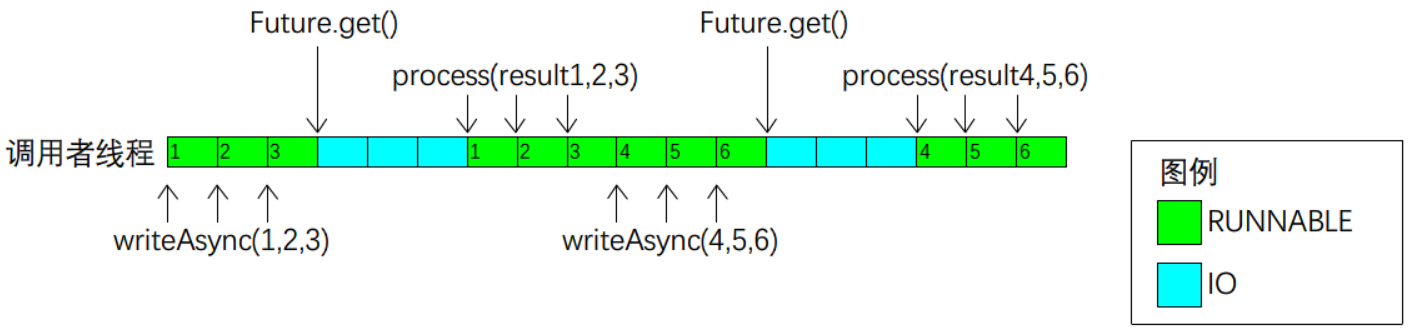
图2-1b 线程时间线:基于线程池的异步IO
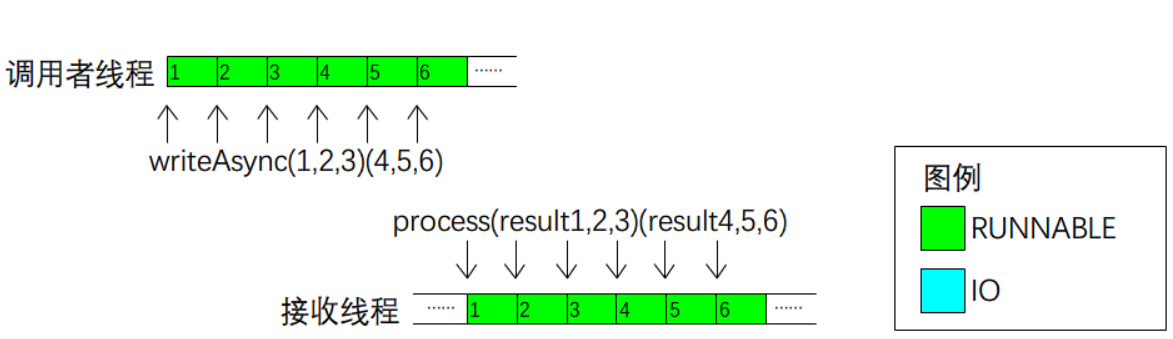
图2-1c 线程时间线:基于Promise的异步IO
2.2 Promise结合线程池
和 ExecutorService+Future相比,Promise具有纯异步的优点;然而在某些场景下也需要把 Promise 和线程池结合使用。例如:1.底层 API 只支持同步阻塞模型,不支持纯异步;此时只能在线程池中调用 API,才能做到非阻塞。2.需要重构一段遗留代码,将其线程模型从线程池模型改为响应式模型;可以先将对外接口改为 Promise API,而底层实现暂时使用线程池。
下面的代码片段展示了 Promise 和线程池结合的用法:
- 创建Promise对象作为返回值。注意这里使用了PromiseOrException,以防期间遇到异常;其可以通知响应数据,也可以在失败时通知抛出的Exception。详见3.1小节。
- 在线程池中执行请求(2a),并在收到响应数据后向Promise通知(2b)
- 处理线程池满异常。线程池底层关联一个BlockingQueue来存储待执行的任务,一般设置为有界队列以防无限占用内存,当队列满时会丢弃某个任务。为了向调用者通知该异常,线程池的拒绝策略须设置为AbortPolicy,当队列满时丢弃所提交的任务,并抛出RejectedExecutionException;一旦捕获该异常,就要向Promise通知请求失败。

3.异常处理:PromiseOrException
Java程序有时会遇到不可避免的异常情况,如网络连接断开;因此,程序员需要设计适当的异常处理机制,以提升程序的容错性。本章介绍异步 API 的异常处理,首先介绍 Java 语言异常处理规范;然后介绍 Promise 的变体PromiseOrException,使得 Promise API 支持规范的异常处理。
3.1异常处理规范
个人认为,Java 代码的异常处理应当符合下列规范:
- 显式区分正常出口和异常出口。
- 支持编译时刻检查,强制调用者处理不可避免的异常。
区分正常出口和异常出口
异常是 Java 语言的重要特性,是一种基本的控制流。Java 语言中,一个函数允许有一个返回值,以及抛出多个不同类型的异常。函数的返回值是正常出口,函数返回说明函数能够正常工作,并计算出正确的结果;相反,一旦函数遇到异常情况无法继续工作,如网络连接断开、请求非法等,就要抛出相应的异常。
虽然 if-else 和异常都是控制流,但是程序员必须辨析二者的使用场景。if-else 的各个分支一般是对等的,都用于处理正常情况;而函数的返回值和异常是不对等的,抛出异常表示函数遇到无法处理的故障,已经无法正常计算结果,其与函数正常工作所产生的返回值有本质区别。在 API 设计中,混淆正常出口(返回值)与异常出口(抛出异常),或者在无法继续工作时不抛异常,都是严重的设计缺陷。
以数据库访问为例,下面的代码对比了API进行异常处理的两种形式。数据库访问过程中,如果网络连接顺畅,并且服务端能够正确处理请求,那么db.write()应该返回服务端的响应数据,如服务端为所写数据生成的自增id、条件更新实际影响的数据条数等;如果网络连接断开,或者客户端和服务端版本不匹配导致请求无法解析,从而无法正常工作,那么db.write()应该抛出异常以说明具体原因。从“是否正常工作”的角度看,上述两种情况的性质是截然不同的,显然应该选用异常作为控制流,而不是if-else。
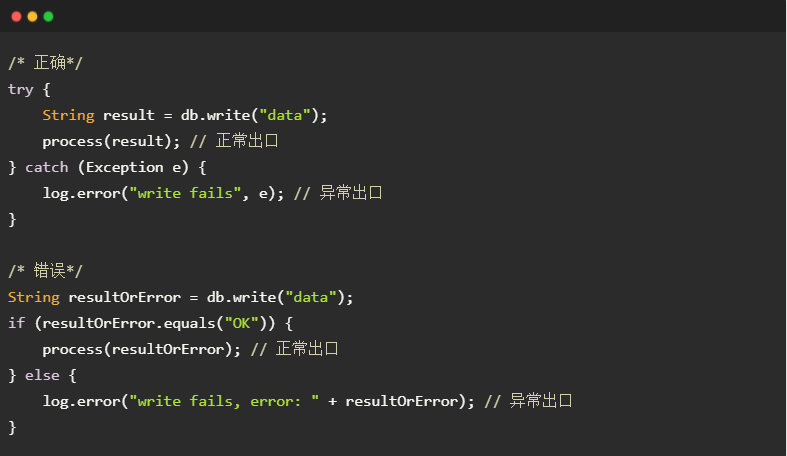
强制处理不可避免的异常
Java语言的异常处理体系中,异常主要分为以下几类:Exception、RuntimeException、Error;三者都是Throwable的子类,即可以被函数抛出。注意,由于 RuntimeException 是 Exception 的子类,本文为避免混淆,“Exception”特指“是Exception但不是RuntimeException”的那些异常。
个人认为,几种异常类型分别用于下列场景:
1. Exception:程序外部的不可抗力造成的异常情况,如网络连接断开。即使 Java 代码完美无瑕,也绝对不可能避免这类异常(拔掉网线试试!)。既然无法避免,这种异常就应当强制处理,以提升系统的容错能力。 2. RuntimeException:编程错误造成的异常情况,如数组下标越界 ArrayOutOfBoundException、参数不符合取值范围 IllegalArgumentException 等。如果程序员对 API 的输入约束了如指掌,并在调用 API 之前对函数参数进行适当校验,那么 RuntimeException 是可以绝对避免的(除非被调 API 在应当抛 Exception 处,实际抛出了RuntimeException)。既然可以避免,这种异常就没有必要强制处理。
当然,人无完人。假设程序员真的违背了某些约束,函数抛出 RuntimeException 且未被处理,那么作为惩罚,线程或进程会退出,从而提醒程序员改正错误代码。如果线程或进程必须常驻,就要对 RuntimeException 进行兜底,如下面的代码所示。这里将代码缺陷视为无法避免的异常情况,捕获异常后可以记录日志、触发告警,提醒稍后来修正缺陷。
new Thread(()->{
while (true){
try{
doSomething();
}catch (RuntimeException e){ // 对RuntimeException进行兜底,以防线程中断
log.error("error occurs", e);
}
}
});
3. Error:jvm内部定义的异常,如 OutOfMemoryError。业务逻辑一般不抛出 Error,而是抛出某种Exception或 RuntimeException。
上述几类异常中,只有 Exception 是强制处理的,称为 checked exception[C]。如下所示是一个 checked exception的例子。数据库访问DB.write()抛出Exception,表示遇到网络断开、消息解析失败等不可抗情况。异常类型为Exception而不是RuntimeException,以强制调用者添加catch子句处理上述情况;如调用者遗漏了 catch子句,则编译器会报错,从而提示调用者“这里一定会遇到异常情况,必须进行处理”,以完善程序容错能力。
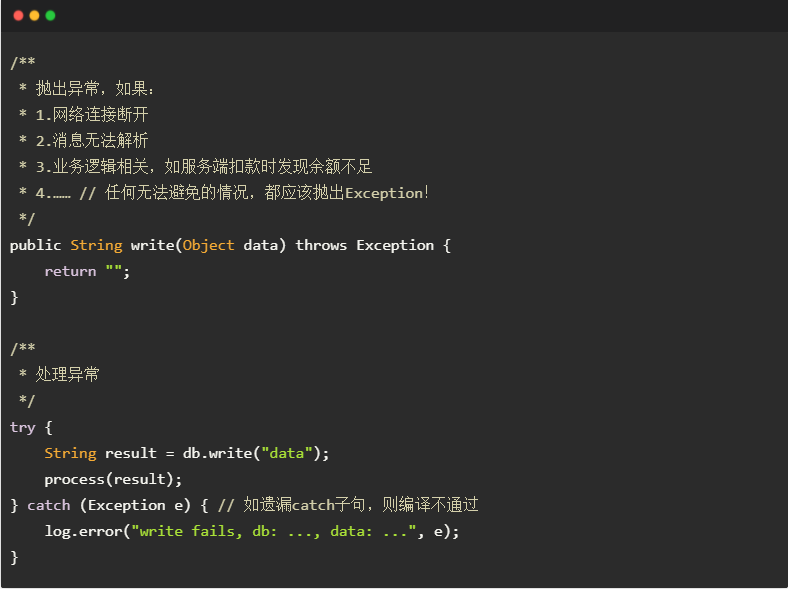
3.2 Promise API的异常处理
上一小节讨论了异常处理的规范:
· 显式区分正常出口和异常出口; · 不可抗的异常,要在编译时刻强制处理。下面的代码展示了 Promise API 要如何设计异常处理机制,以符合上述规范。
- 使用PromiseOrException来通知响应数据和异常。PromiseOrException<T, E>是Promise
的子类,泛型模版X为数据对象ResultOrException<T, E extends Exception>,其含有2个字段result和e:e==null表示正常,此时字段result有效;e!=null表示异常,此时不要使用字段result。 - 在“重载1”中,调用者从回调函数中获得ResultOrException对象。调用ResultOrException.get()获取响应数据result,或者get()方法抛出异常e。这种方式的代码结构和传统的异常处理一致,可以使用多个catch子句分别处理不同类型的异常。
- 在“重载2”中,调用者从回调函数中直接获得result和e。含义同上。这种方式省去了ResultOrException.get();但是如果需要处不同类型的异常,则需要用e instanceof MyException来判断异常类型。
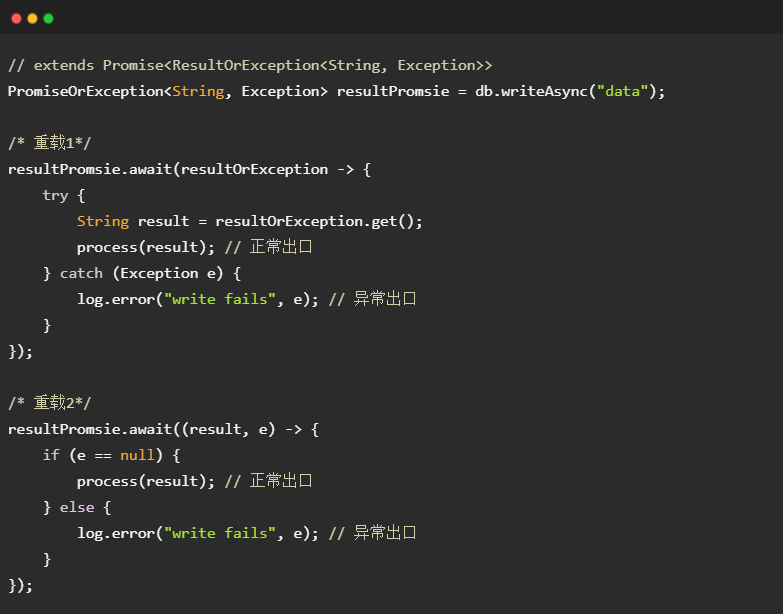
PromiseOrException符合上一小节提出的异常处理规范,具有如下优点:
- 区分正常出口和异常出口。响应数据和异常分别使用 result 和e两个变量来传递,可以靠e==null来判断是否正常。注意result==null不能作为判断条件,因为null有可能是响应数据的合法值。
- 强制处理异常。不论使用哪一种回调,不存在一种代码结构能够只获得 result 而不获得e,因此语法上不会遗漏e的异常处理。
- 允许定义异常类型。PromiseOrException 的泛型模版E填为 Excetion 不是必需的,也可以填为任意其他类型。注意,受限于 Java 语法,泛型模版处只允许填写一种异常类型,而不像函数抛异常那样允许抛出多种异常。为应对这种限制,我们只能为 API 定义一个异常父类,调用者用 catch 子句或 instanceof 进行向下转型。当然,这种“定义异常父类”的做法也是可以接受的,并在现有工具中广泛应用,因为可以将工具所抛异常区别于Java语言内置的异常类型。
最后,在异常处理结构方面个人提出一个建议:全部异常通过 PromiseOrException 来通知,而 API 本身不要抛出异常。以数据库访问 API writeAsync()为例,面的代码对比了两种抛异常的方式。正确的做法是PromiseOrException 作为唯一出口,如果 API 底层实现抛出异常(submit() throws Exception),则应该将异常封装于 PromiseOrException 对象,而不应该直接从API函数抛出(writeAsync() throws Exception)。
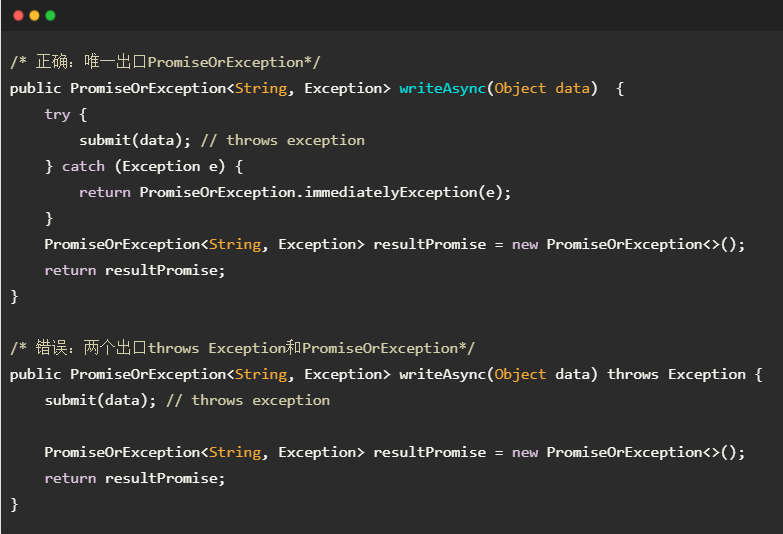
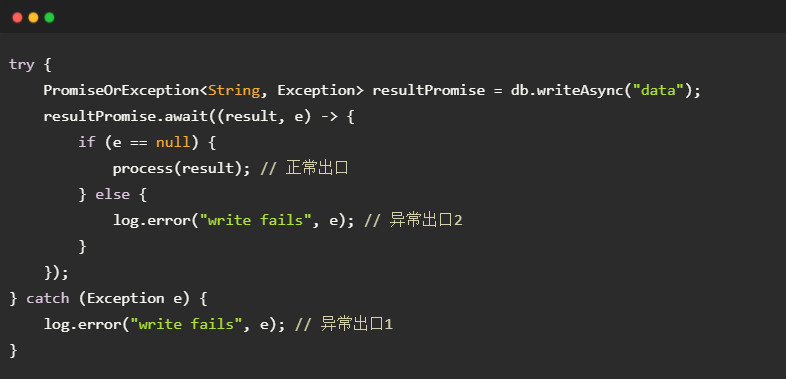
如果错误地设计了含有两个异常出口的 API,调用者就不得不重复书写异常处理逻辑,如下面的代码所示。
4.请求调度
Java 程序中有时需要提交多条异步请求,且这些请求之间存在一定的关联关系。在异步非阻塞场景下,这些关联关系都可以借助 Promise 来实现。
1.顺序请求,如图4-1所示。后一条请求依赖前一条请求的响应数据;因此,必须等待前一条请求返回,才能构造并提交下一条请求。

图4-1 顺序请求
2.并行请求,如图4-2所示。一次提交多条请求,然后等待全部请求返回。所提交的请求之间没有依赖关系,因此可以同时执行;但是必须收到每条请求的响应数据(发生channelRead()事件,事件参数为响应数据),才能执行实际的处理process(result1,2,3)。

图4-2 并行请求
3.批量请求,如图4-3所示。调用者连续提交多条请求,但是暂存在队列中(offer()),而不是立刻执行。一段时间后,从队列中取出若干条请求,组装为批量请求来提交(writeBulk());当收到批量请求的响应消息时,可以从中取出每条请求的响应数据。由于每次网络IO都带来额外开销,故实际应用中经常使用批量请求来减少网络IO频率,以提升总体吞吐量。
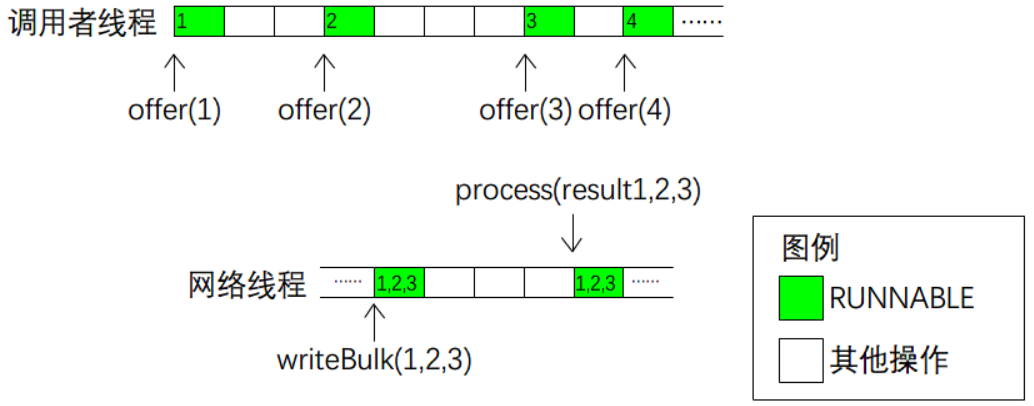 图4-3 批量请求
图4-3 批量请求
4.1.顺序请求:Promise.then()
假设一系列操作需要依次完成,即前一操作完成后,才能开始执行下一操作;如果这些操作均表现为 Promise API,我们可以对 Promise.await(listener)进行封装,使代码结构更加简洁。
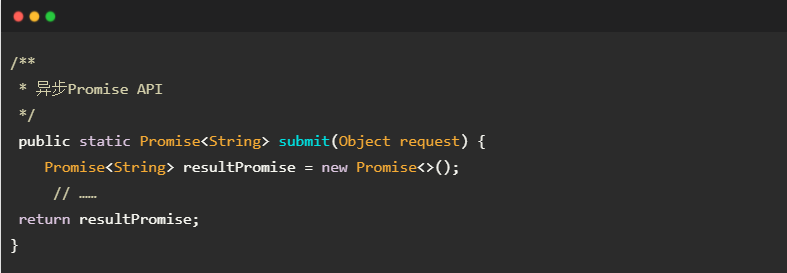
如下所示是一个异步 Promise API。submit 方法提交请求 request 并返回 Promise 对象;当收到响应数据时, 该 Promise 对象被通知。
现假设有5个请求称为“A”-“E”,这些请求必须依次提交。例如,由于请求B的参数依赖请求 A 的响应数据,故提交请求A后必须先处理其响应数据 resultA,然后才能再提交请求B。这种场景可以用如下所示的代码来实现。某次调用submit(“X”)函数后,我们在其返回的 Promise 对象上注册回调;回调函数内处理响应数据 resultX,并调用submit(“X+1″)来提交下一请求。
这种方式虽然能实现功能需求,但是嵌套式的代码结构可读性非常差——每增加一个请求,代码就要多嵌套、缩进一个层级。当调用逻辑复杂、请求数较多时,代码会非常难以维护。
这种情况也称为 “回调地狱”[D],在 JavaScript 语言中相关讨论颇多,可以作为参考。
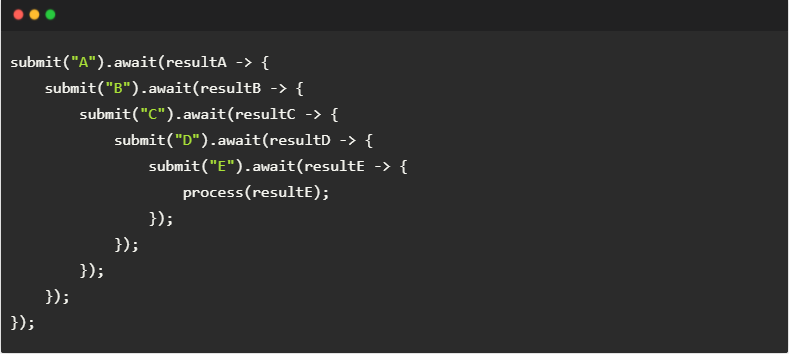
为改进代码结构,我们对 Promise

接下来,我们将中间变量 resultPromiseA-E 内联,即得到基于then()的链式调用结构。相比于await(),then()消除了套娃般的嵌套回调。
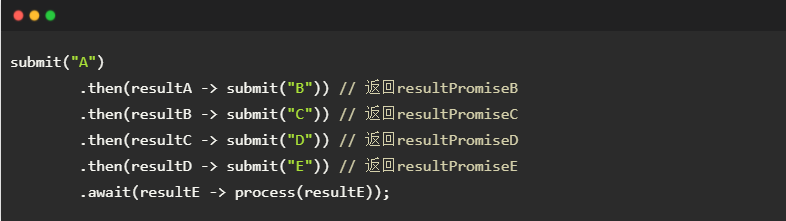
最后,我们来看一下 Promise
- then()方法提供一个泛型模版Next,以说明下一请求的响应数据类型。
- 根据泛型模版Next,then()内部创建Promise
作为返回值,用于通知下一请求的响应数据。 - 对于当前请求,调用await()注册响应数据的回调result;当收到响应数据后,执行函数func,以提交下一请求:func.apply(result)。
- 当收到下一请求的响应数据后,Promise
被通知:nextPromise::signalAll。
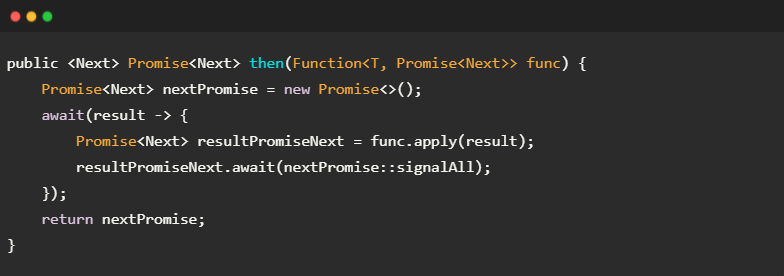
注意,这里只展示了纯异步重载Promise
thenRun(Runnable)
thenAccept(Consumer
thenApply(Function<T, Next>)
thenApplyAsync(Function<T, Promise
4.2.并行请求:LatchPromise
上一小节介绍了“顺序请求”的场景,即多条请求需要依次执行;而“并行请求”场景下,多条请求之间没有顺序约束,但是我们仍然需要等待全部请求返回,才能执行后续操作。例如,我们需要查询多张数据库表,这些查询语句可以同时执行;但是必须等待每条查询都返回,我们才能获得完整信息。jdk提供CountDownLatch来实现这一场景,但是其只支持同步等待;作为改进,我们采用LatchPromise实现相同的功能,并且支持纯异步API。
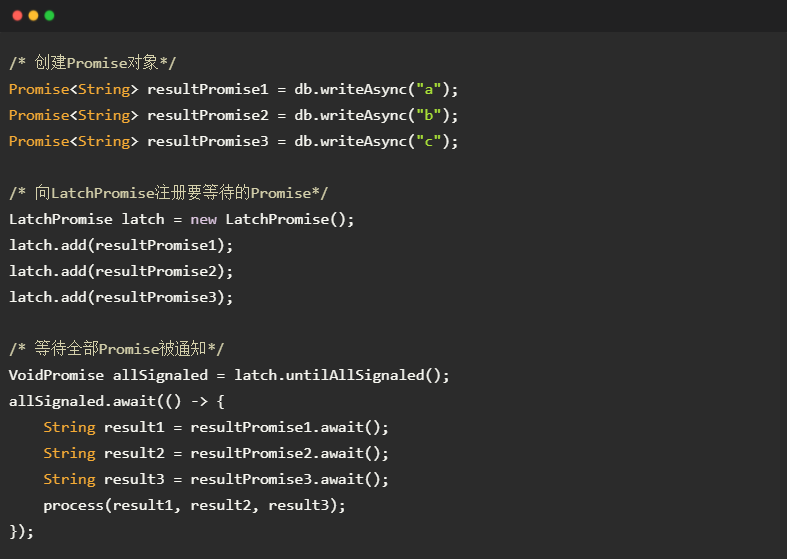
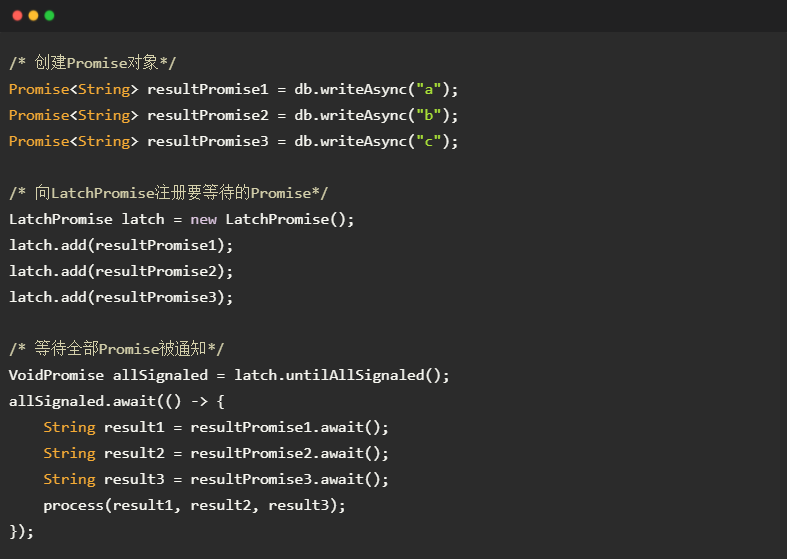
以数据库访问为例,如下所示的代码展示了LatchPromise的使用:
- 提交3条请求,并获取每个请求所对应的Promise对象resultPromise1-3,以获取响应数据。
- 创建LatchPromise对象,并向其注册需要等待的Promise对象resultPromise1-3。
- LatchPromise.untilAllSignaled()返回一个Promise对象allSignaled。当所注册的resultPromise1-3均被通知后,allSignaled会被通知。allSignaled的类型为VoidPromise,表示allSignaled被通知时没有需要处理的响应数据。
- 在allSignaled上注册回调,在回调函数中调用resultPromiseX.await()获取实际的响应数据;此时由于请求已执行完毕,故await()立刻返回而不阻塞。
作为对比,下面的代码使用 CountDownLatch 实现相同功能,但是存在以下缺陷:
- CountDownLatch.await() 只支持同步等待。在纯异步场景下是无法接受的。
- CountDownLatch 对业务逻辑有侵入性。程序员需要在业务逻辑中添加对 CountDownLatch.countDown()的调用,以控制CountDownLatch 的时序;相反,LatchPromise 依赖本来就已经存在的 resultPromise 对象,而不需要编写额外的时序控制代码。
- CountDownLatch 引入了冗余逻辑。创建 CountDownLatch 时,必须在构造参数中填写要等待的请求数;因此,一旦所提交的请求的数目改变,就必须相应地更新创建 CountDownLatch 的代码,修改构造参数。
最后,我们来看一下** LatchPromise 的参考实现**。代码原理如下所示:
- 设立countUnfinished变量,记录还没有被通知的Promise对象的数目。每当注册一个Promise对象,countUnfinished递增;每当一个Promise被通知,countUnfinished递减。当countUnfinished减到0时,说明所注册全部Promise对象都被通知了,故通知allSignaled。
- 设立noMore变量,记录是否还需要继续注册新的Promise对象,仅当调用了untilAllSignaled()才认为完成注册;在此之前,即使countUnfinished减至0,也不应该通知allSignaled。考虑这样一种情况:需要注册并等待resultPromise1-3,其中resultPromise1、2在注册期间即已被通知,而resultPromise3未被通知。如果不判断noMore,那么注册完resultPromise1、2后,countUnfinished即已减至0,导致提前通知allSignaled;这是一个时序错误,因为实际上resultPromise3还没有完成。
- 为保证线程安全,访问变量时须上锁,此处使用synchronized来实现。
- 注意,调用untilAllSignaled()时,如果countUnfinished的初值已经为0,则应立刻通知allSignaled;因为countUnfinished已经不可能再递减,之后没有机会再通知allSignaled了。
// private static class Lock。无成员,仅用于synchronized(lock)
private final Lock lock = new Lock();
private int countUnfinished = 0;
private final VoidPromise allSignaled = new VoidPromise();
public void add(Promise<?> promise) {
if (promise.isSignaled()) {
return;
}
synchronized (lock) {
countUnfinished++;
}
promise.await(unused -> {
synchronized (lock) {
countUnfinished--;
if (countUnfinished == 0 && noMore) {
allSignaled.signalAll();
}
}
});
}
public VoidPromise untilAllSignaled() {
synchronized (lock) {
if (countUnfinished == 0) {
allSignaled.signalAll();
} else {
noMore = true;
}
}
return allSignaled;
}
4.3.批量请求:ExecutorAsync
批量请求的特性
“批量请求”(也称“bulk”、“batch”)是指发送一条消息即可携带多条请求,主要用于数据库访问和远程调用等场景。由于减少了网络 IO 次数、节约了构造和传输消息的开销,批量请求能有效提升吞吐量。
很多数据库 API 都支持批量读写,如JDBC PreparedStatement[E]、elasticsearch bulk API[F]、mongo DB insertMany()[G]、influx DB BatchPoints[H],读者可以查阅参考文献进一步了解。为了提升性能,部分API会牺牲易用性。其中,elasticsearch bulk API 对调用者的限制最少,允许混杂增删改等不同类型的请求,允许写入不同的数据库表(index);mongo DB、influx DB 次之,一个批量请求只能写入同一个数据库表,但是可以自定义每条数据的字段;PreparedStatement 的灵活性最低,其定义了 SQL 语句的模版,调用者只能填写模版参数,而不能修改语句结构。
虽然数据库 API 已经支持批量访问,但是很多原生 API 仍然需要调用者自己构造批量请求,需要调用者处理请求组装、批量大小、并发请求数等复杂的细节。
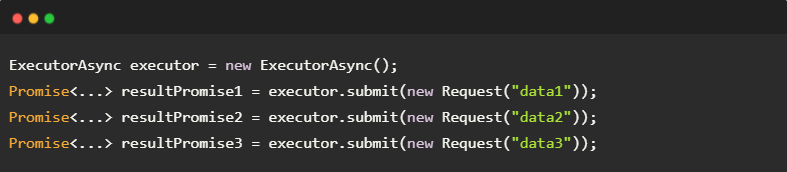
在此,我们设计出通用组件 ExecutorAsync,封装请求调度策略以提供更简洁的API。ExecutorAsync 的使用流程如下面的代码片段所示:
- 类似于线程池 ExecutorService.submit(),调用者可以调用ExecutorAsync.submit()来提交一个请求。其中,请求以数据对象 Request 表示,用于存储请求类型和请求参数。
- 提交请求后,调用者获得 Promise 对象,以获取响应数据。由于使用了 Promise,ExecutorAsync 支持纯异步操作,提交请求和获取响应数据都不需要阻塞。
- ExecutorAsync 内部对请求进行调度,并非提交一条请求就立刻执行,而是每隔固定时间收集一批请求,将其组装为一个批量请求,再调用实际的数据库访问 API。如果数据库访问 API 允许,那么一批请求可以混杂不同的请求类型,或者操作不同的数据库表。
具体而言,ExecutorAsync 支持如下调度策略:
1.排队,如图4-4a所示。调用者提交请求Request后不要立刻执行,而是将其缓存在队列queue中。
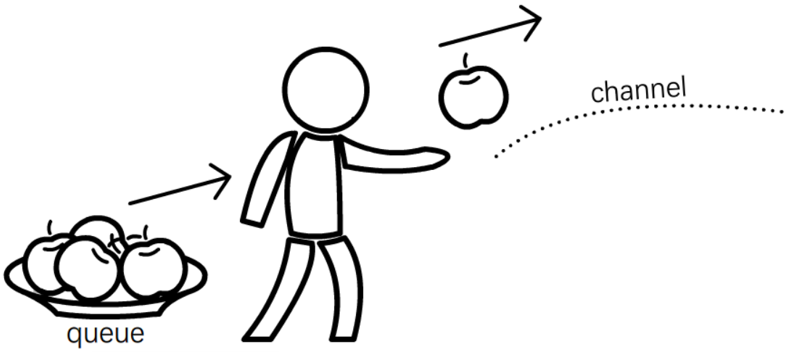
图4-4a ExecutorAsync特性:排队
2.批量,如图4-4b所示。每隔固定时间间隔,ExecutorAsync从队列中取出若干条请求,将其组装为批量请求bulk,并调用底层数据库API提交给服务端。如果队列长度增长得很快,我们也可以定义一个批量大小bulk size,当队列长度到达该值时立刻组装一个批量请求并提交。
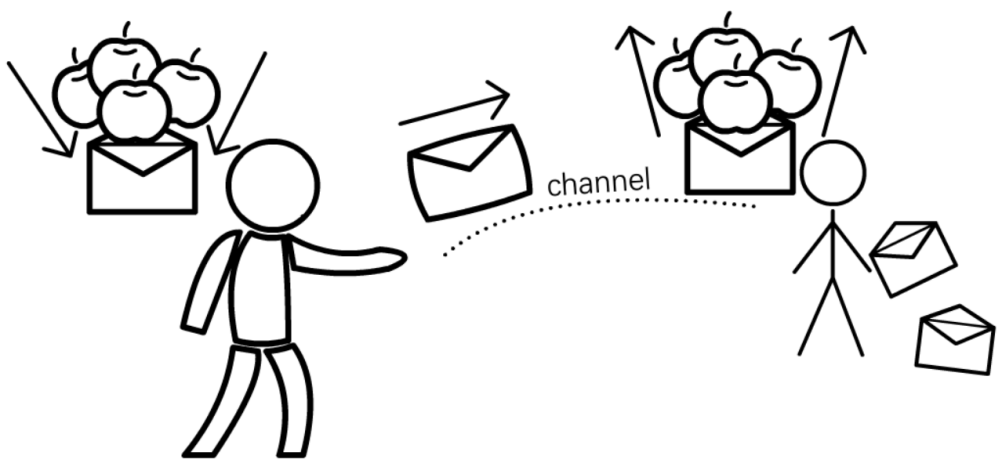 图4-4b ExecutorAsync特性:批量
图4-4b ExecutorAsync特性:批量
3.并发,如图4-4c所示。如果底层数据库API支持异步提交请求,那么ExecutorAsync就可以充分利用这种特性,连续提交多个批量请求,而不需要等待之前的批量请求返回。为避免数据库服务器超载,我们可以定义并发度parallelism,限制正在执行(in flight)的批量请求的数目;当达到限制时,如果调用者再提交新的请求,就暂存在队列queue中等待执行,而不会组装新的批量请求。
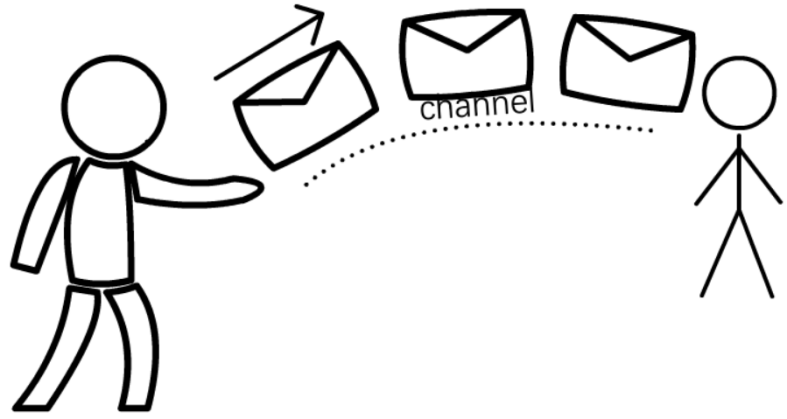
图4-4c ExecutorAsync特性:并发
4.丢弃。如图4-4d所示。在上文提到的bulk size和parallelism的限制下,如果提交请求的速率远高于服务端响应的速率,那么大量请求就会堆积在队列中等待处理,最终导致超时失败。在这种情况下,将请求发送给服务端已经没有意义,因为调用者已经认定请求失败,而不再关心响应数据。
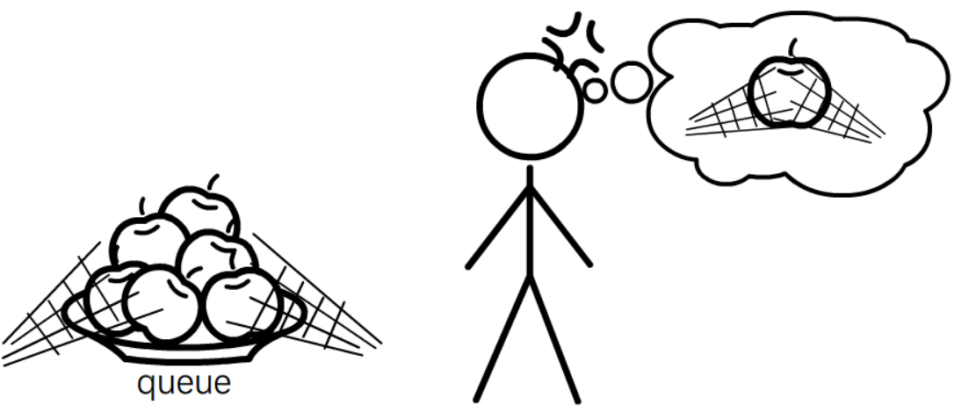
图4-4d 请求超时
因此,ExecutorAsync应该及时从队列中移除无效请求,而剩余请求仍然“新鲜”。这种策略能够强制缩短队列长度,以降低后续请求在队列中的堆积时长、预防请求超时;同时,由于避免存储和发送无效请求,这种策略也能节约内存和 IO 开销。
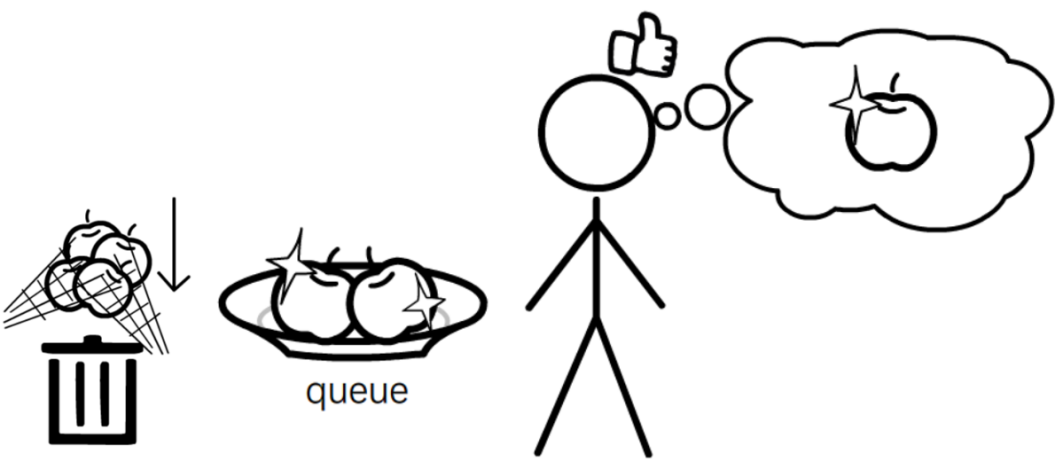 图4-4e ExecutorAsync特性:丢弃
图4-4e ExecutorAsync特性:丢弃
批量请求的实现
上一小节我们看到了 ExecutorAsync 的调度策略,包括排队、批量、并发、丢弃。如下面的代码所示,ExecutorAsync只需对外提供 submit(Request) 方法,用于提交单条请求。请求以数据对象 Request 表示,其字段 Request.resultPromise 是 Promise 对象,用于通知响应数据;在需要进行异常处理的场景下,我们使用 PromiseOrException<T, Exception>作为 Promise 的实现,其中泛型模版T改为响应数据的实际类型。
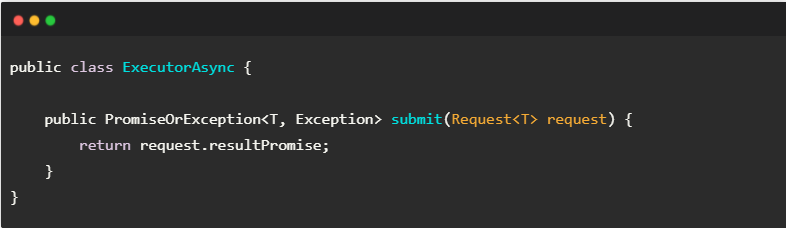
接下来我们来看看 ExecutorAsync 的实现原理。由于源码细节较多、篇幅较长,故本节用流程图的形式,来讲解更高层的设计,如图4-5所示。
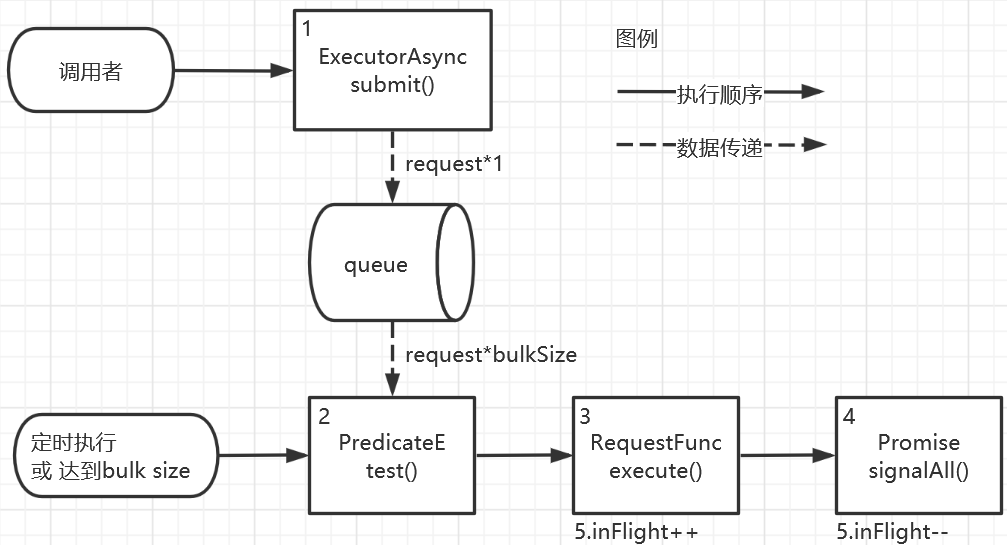
图4-5 ExecutorAsync原理
1.提交请求。调用者调用 ExecutorAsync.submit(Request),每次调用提交一条请求。该条请求存入队列 queue,等待后续调度执行。参数 Request 的结构如下面的代码所示,包括下列字段:
predicate:函数,判断请求是否有效,无效请求(如超时的请求)将被丢弃。详见步骤2。
resultPromise:通知响应数据。

2.每隔固定间隔,或者queue.size()达到bulk size,尝试组装批量请求。从队列queue中依次取出请求,每条请求执行函数Request.predicate,以判断是否仍然要提交该请求;取出的有效请求的条数,不超过bulk size。 predicate是一个函数,类似于jdk Predicate接口,形式如下面的代码所示。接口函数test()可以正常返回,表示请求仍然有效;也可以抛出异常,说明请求无效的原因,如等待超时。如果抛出异常,则该条请求直接丢弃,并将发生的异常将通知给Request.resultPromise,使得调用者执行异常处理逻辑。

3.提交批量请求。第2步从队列queue中取出了至多bulk size条请求,将其作为参数调用RequestFunc.execute(requests),以提交批量请求。接口RequestFunc的形式如下面的代码所示。接口方法execute(requests)以若干条请求为参数,将其组装为批量请求,调用底层的数据库API来提交。

4.当收到响应后,对于每条请求,依次向 Request.resultPromise 通知响应数据。
5.为防止服务端超载,ExecutorAsync可限制并发请求数不超过 parallelism。我们设置计数变量 inFlight=0,以统计正在执行的批量请求数:
a.当尝试组装批量请求(步骤2)时,首先判断inFlight<parallelism,满足条件才能从队列queue中取出待执行的请求。
b.当提交批量请求(步骤3,RequestFunc.execute())后,inFlight++。
c.当一批请求均收到响应数据(步骤4,Request.resultPromise被通知)后,inFlight–。此时如queue中的请求数仍超过bulk size,则回到步骤2,再取出一批请求来执行。
综上,ExecutorAsync使用队列queue来暂存待执行的请求;当需要提交批量请求时,以PredicateE筛选有效请求、丢弃无效请求;对于一批请求,调用RequestFunc.execute()来批量提交,收到响应数据后Request.resultPromise通知。上述过程满足约束,以防服务端超载:一批请求的数目至多为bulk size;同时正在执行的批量请求数不超过parallelism。以上即为ExecutorAsync的基本原理;实际应用中还需要处理配置参数、泛型模版等细节,限于篇幅原因本文不再详细讲解。
5.总结
本文介绍了异步模型和Promise设计模式的实际应用场景,讨论了异步API的设计原则,并介绍了相应的解决方案。异步模式不仅仅是“提交请求-处理响应”的简单过程,有时也需要设计异常处理机制,以及根据请求之间的关联关系进行调度。在处理这些复杂场景的时候,API需要保持纯异步的特性,在提交请求、处理响应的过程中都不能阻塞;需要充分利用编译时刻检查,防止调用者遗漏分支,尤其是不可避免的异常分支;API需要封装复杂的、重复的实现细节,尽量保持调用者的代码结构简洁易懂。
本系列文章旨在对异步模式进行科普,希望能起到抛砖引玉的作用,帮助读者理解异步模式的基本原理,对有可能遇到的实际问题有所了解,并初步探索异步模式的实现机制。然而,现实中的项目和工具远比本文介绍的复杂,还请读者做好调研、选型工作。考察现有的各种异步API,读者会发现异步模式目前仍无统一标准。以数据库客户端为例,各种异步API的函数形式都不尽相同,listener API和Promise API都有采用,也有一些API形式上是异步的,但是在某些情况下会发生阻塞;异步API底层有基于线程池/连接池实现的,也有基于响应式模型(如netty)实现的。因此,请读者务必充分了解异步工具的API形式、阻塞特性、线程模型,然后才能在项目中应用;如果现有工具不符合开发规范,亦可大胆地进行封装,或者自行实现所需特性。关于异步工具的封装和实现,也非常欢迎读者交流与指正。
参考文献
[A] jdk CompletableFuture
https://www.baeldung.com/java-completablefuture
[B] netty DefaultPromise
https://www.tabnine.com/code/java/classes/io.netty.util.concurrent.DefaultPromise
[C] checked exception
https://www.geeksforgeeks.org/checked-vs-unchecked-exceptions-in-java/
[D] 回调地狱(JavaScript)
https://blog.avenuecode.com/callback-hell-promises-and-async/await
[E] 批量请求:JDBC PreparedStatement
https://www.tutorialspoint.com/jdbc/jdbc-batch-processing.htm
[F] 批量请求:elasticsearch bulk API
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html
[G] 批量请求:mongo DB insertMany()
https://mongodb.github.io/mongo-java-driver/3.0/driver-async/getting-started/quick-tour/
[H] 批量请求:influx DB BatchPoints
https://github.com/influxdata/influxdb-java/blob/master/MANUAL.md

 微信
微信

 新浪微博
新浪微博

 有道云笔记
有道云笔记