yumeng(有道开发工程师)
一、需求是什么?
互联网中的许多应用都有数据实时更新的需求,比如网页搜索如何展示几分钟之前的新闻结果,购物搜索中价格、库存信息的实时更新。在大数据量的情况下,数据如何做到稳定及时的更新?本文以有道购物搜索(惠惠网)价格更新为例,介绍一下数据实时更新系统的服务器端设计方案。
1.1 痛点之一:大数据
不管是网页搜索的时效性内容展示,还是购物搜索海量商品的价格、库存信息。都是单机较难承受的,同时,大数据对系统的可扩展性,以及运维的稳定性都提出了挑战。网页搜索是几百亿量级,购物搜索是几亿商品量级。
1.2 痛点之二:实时性
如果只是大数据,我们可以用时间换空间,传统的慢慢的批量更新就好。但很多实际应用,用户需要第一时间掌握最新的消息(网页搜索场景,分钟级别的最新新闻),用户可能几分钟之内就下单,需要了解当前最准确的价格和库存信息(购物场景,热门商品价格和库存变化之后,分钟级别的更新到前台)。实时性不可或缺。
下面具体展示几个使用到实时价格和库存等信息的产品例子。如图 1 所示,购物搜索的详情页中展示了多个来自价格服务器的相关信息。其中用红色椭圆标记的商品价格即为商品的实时价格,用蓝色椭圆标记的价格变化趋势是对商品历史价格的变动趋势概括,用土黄色椭圆标记的库存状态表示该商城的此商品已经处于缺货状态。通过点击“价格下降”的趋势图标,可以弹出图 2 所示的该商品的价格历史截图。不仅购物搜索会使用到实时的价格和库存数据,购物助手在展示比价和价格历史的时候也使用了实时的价格数据,如图 3 所示,蓝色圈起来的是价格历史,红色圈起来的是其它商家的实时价格。
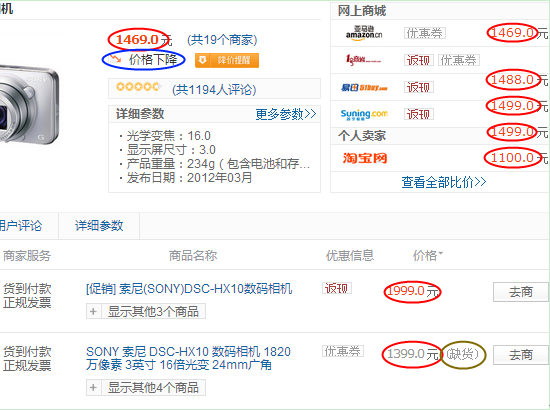
图1 搜索详情页中价格服务提供的数据截图

图2 索尼HX10数码相机的价格历史截图
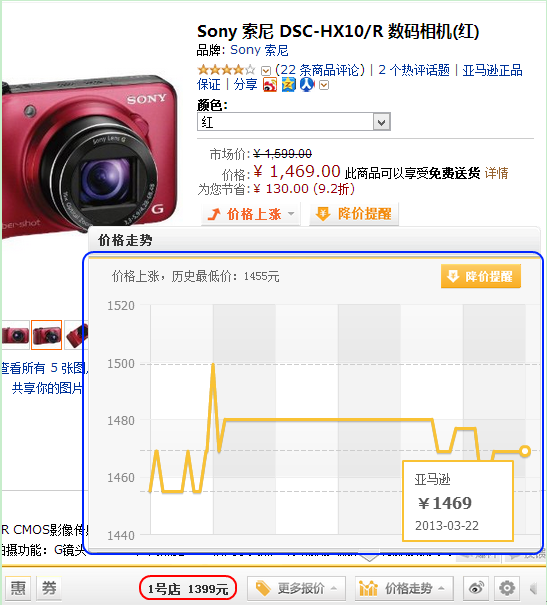
图3 购物助手的展示示例
通过以上产品展示,我们知道在购物搜索与比价等产品中,精准的价格与库存信息直接影响着用户对产品的信赖。因此,这些关键数据的更新速度对整个产品而言就变得至关重要。在传统的搜索引擎系统中,数据的抓取与更新一般由后台驱动完成,即:以固定的时间以一定的频率和策略进行数据抓取,抓到的数据与用户的查询之间有一段“不可接受的”的时间间隔,而这段数据缓存时间往往导致数据过期,使得搜索的结果不够准率。对于购物搜索而言,目前的大型电商网站的商品价格经常会变动,平均每分钟 B2C 价格变化的商品大概在 1500 左右。后台的批量抓取在价格更新方面往往不够及时,为了在任意时刻都能够为用户提供更准确的商品价格,我们为处理商品价格开发了一个新的服务,价格服务器。
价格服务器这个数据实时更新系统的设计需要解决两个关键的问题:1、大规模数据抓取与更新,满足用户商品检索需求的购物商品数是几亿量级。2、价格、库存数据的实时性。商品价格/库存变化,希望能做到分钟级别的更新,尤其是用户关注浏览的热门商品。这些大量数据的更新能力,主要取决于我们自身的抓取能力,同时还依赖于目标电商网站的承受能力。而且价格数据的实时性则关系到用户对产品的信赖度,直接影响着用户在搜索或比价结果中作出的选择。同时,价格的实时性也关系着所有依赖于它的其它服务的实效性,因为在价格更新的同时,也会触发全网比价和降价提醒等服务的数据更新。
二、整体架构设计
价格服务器的整体架构设计包含了两方面的特性:分布式特性和实时特性。下面分别介绍其必要性和具体实现。
2.1 分布式特性
随着电商行业的飞速发展,商品的数量也在不断的快速增加,集中式结构的 可扩展性相对较差,因此整个系统必须使用分布式的体系,将繁杂的不同的任务分配给若干个独立的系统并行处理,能够极大地提高了系统的性能和可扩展性。
如图4 所示,价格服务器的分布式体系中主要由三种服务构成:任务调度服务器、抓取服务器、结果入库服务器,分别对应图中的 PriceServer、PriceUpdateServer 和 PriceWriteBackServer,这三种服务采用 RPC(远程过程调用)的方式进行相互调用。其中任务调度服务器同时提供对外数据查询的功能。由于系统的分布式特性,这三种服务每个都可以有多个实例,可以根据系统的实际需求随时进行扩容。其中,最先可能遇到瓶颈的就是抓取服务器,分布式的架构可以简单快捷地通过增加机器来对系统扩容,进而增加系统的抓取能力。分布式特性同时可以提高系统的稳定性,当某一台服务不可用时,同类别的其它服务器仍可以正常运行,减少由于服务宕机导致产品不能使用的概率。
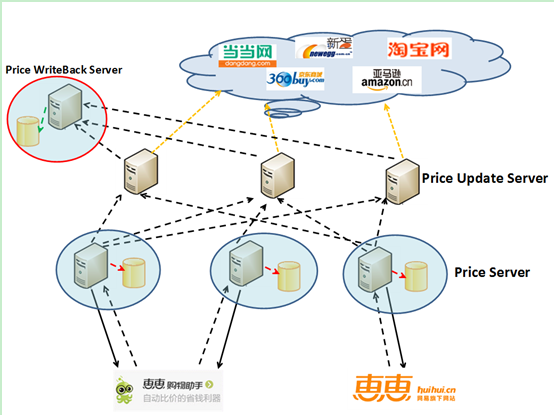
图4 价格服务器的层次结构
2.2 实时特性
整个系统的实时特性主要体现在两个方面:1、数据更新的实时性;2、数据变化后通过其它服务的实时性。
2.2.1 基于查询的实时抓取
在海量的商品面前,由于抓取能力有限,根本无法满足快速地更新所有的商品的价格信息,为了保证用户对于数据高实时性的要求,应该尽可能地优先保证热门商品的数据更新,所以实时抓取的商品选择是比较关键的。我们的系统使用购物助手的浏览记录以及购物搜索的查询记录当作热门商品。具体流程为:用户浏览某商品,购物助手获取该用户所浏览的商品 URL 以及其它商城该商品的 URL 列表发送到任务调度服务器,任务调度服务器根据上一次抓取的价格时间等信息来进行调度,将任务分配至抓取服务器,抓取服务器解析到新的价格后发送到结果入库服务器。结果入库服务器完成数据的更新,并通知其它价格事件监听程序。这就完成了整个基于查询驱动的实时抓取的过程。这种实时抓取策略就叫做“查询驱动抓取”(简称 QTC,Query Triggered Crawling)。
2.2.2 数据变化的实时通知
价格服务器除了实时抓取和管理所有商品的价格之外,还需要向其它服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何使得其它服务可以实时地得到商品的价格变化信息呢?我们首先介绍一下观察者模式。
观察者模式(也被称为发布/订阅模式)是软件设计模式的一种。在此种模式中,一个目标对象管理所有相依于它的观察者对象,并且在它本身的状态改变时主动发出通知。这通常透过呼叫各观察者所提供的方法来实现。此种模式通常被用来实作事件处理系统。
观察者模式已经在数据变化的实时通知方面被广泛地应用,它使得服务具有高类聚、低耦合的特点。下面来介绍两个使用了类似观察者模式的成熟的系统,分别是 Google的咖啡因(Google Caffeine)索引系统和 Linkedin 的 Databus 数据传输总线。
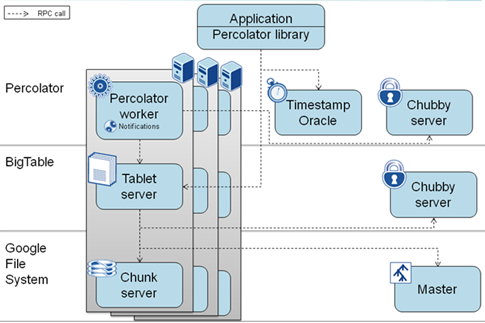
图5 Google 咖啡因架构
图 5 是 Google 的咖啡因索引架构:Percolator 是基于分布式存储系统 BigTable 的,核心在于实现了对每个文档的随机访问。Percolator 的观察者模式(observer)可以在底层数据特定列发生更新之后,被系统调用,从而实现上层应用的及时更新。在网页搜索领域里,传统的索引更新方案是基于 MapReduce 和其他批处理系统定时更新的,这使得索引的更新至少需要等待一轮完整的大数据处理流程完成。即使是一轮增量数据处理,相对于实际应用需要,依然是漫长不太可接受的。
再来看另外一个架构,前不久,Linkedin 公布了一个其内布使用的 Databus 项目。如图 6 所示,Databus 的主要原理是当任何数据库有更新时,通过分析数据库的更新日志,将所有的数据更新事件传输到 Databus 总线上,进而通过各个其它服务更新数据。数据源发生完成后,Databus 能在微秒级内将事务提交给消费者。同时,消费者使用 Databus 中的服务器端过滤功能,可以只获取自己需要的特定数据。
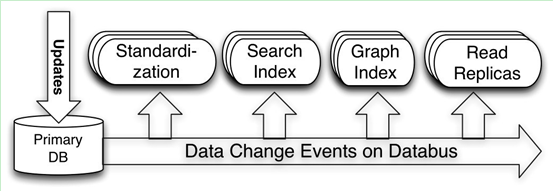
图6 Linkedin 的 Databus 数据传输总线概要结构
显示易见,Databus 的设计思路与 Percolator 的观察者模式非常相似。因此,我们在价格服务器中也使用了类似的设计,将实时更新的价格变化事件通知到一系列其它的产品服务中(如降价提醒、全网比价等)。
如图 7 所示,在价格服务器的系统中,结果入库服务器是所有价格数据更新的必经之地,它从数据源得到最新的价格数据,通过对比底层存储中的旧数据,就可以直接获取到所有的价格变化,进而更新数据库中的价格、历史、趋势等信息。它利用观察者模式,将所有的价格变化事件传送到其它监听服务(如降价提醒、全网比价等)。每个监听服务会根据自身的需求过滤掉没有用的事件,因此像降价提醒这种服务可以实时地提醒用户某个商品的降价消息。
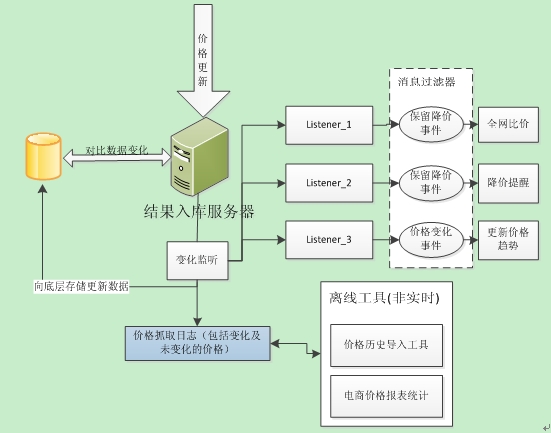
图7 结果入库服务器触发其它服务的数据流程
同时,如图 7 所示,结果入库服务器还会将所有的价格更新信息以日志的形式记录下来,后台的非实时的分析工具通过这些日志构建价格历史、电商价格报表等。
三、数据源
如图 8 所示,价格服务器的价格更新主要来源有三个:1、抓取服务器的实时抓取;2、合作电商主动提供的数据;3、后台定时批量抓取和解析的流程。
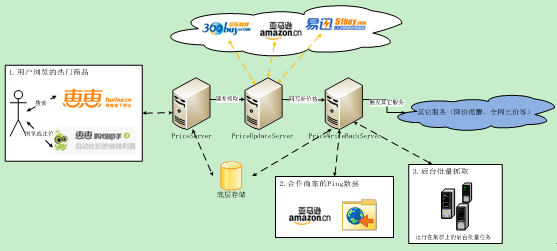 图8 商品价格数据来源
图8 商品价格数据来源
这三种数据更新来源,最能保证数据实效性的是抓取服务器的实时抓取,前文已经描述它的工作原理。虽然实时抓取可以最大程度地满足用户查询结果的实效性,但是覆盖率相对较低,因此还需要其它数据源的配合才能提高商品价格更新的覆盖率。和绝大多数搜索引擎相同,购物搜索的后台也会定时批量地抓取大量的商品数据。同时,我们与一些商家进行了合作,这些商家会定时主动向我们的系统推送他们最新的商品数据,这些数据也包括价格和库存等信息。有了后台定时批量抓取流程和合作商家的推送数据,几乎就使得绝大多数商品的数据可以得到及时地更新了。
除此之外,还会利用其它服务的日志离线触发价格服务器更新用户感兴趣的商品的价格数据。例如:利用用户订阅的降价提醒商品列表定期更新这些用户感兴趣的商品的价格。又如:全网比价展示了所有最新降价的商品,这些商品的价格是否又回升了对全网比价的质量影响很大,因此,全网比价的商品列表也需要经常被更新,以防止过时的降价信息影响用户体验度。
总结一下,数据来源的使用主要有三点。第一、尽可能地利用多种数据来源,使价格能够被更快速及时地更新;第二、首先保证热门商品的价格被及时更新,热门商品的列表来自于用户的浏览记录与搜索历史等;第三、不能忽略非热门的商品,非热门商品虽然被用户访问的次数少,但也需要定期地被更新,只是更新间隔略长一些。
四、总结
本文主要以购物搜索价格服务器,辅以 Google 咖啡因,Linkedin 的 Databus 为例,介绍了大数据实时更新框架的设计思想。框架的共同点是:1、观察者模式,2、细粒度的更新数据到应用层。对比过去 MapReduce 的批量更新机制,更好的解决了大数据和实时性这两大痛点。

 微信
微信

 新浪微博
新浪微博

 有道云笔记
有道云笔记
感觉非常有帮助,非常感谢