背景篇
NLPCC的全称为“CCF国际自然语言处理与中文计算会议”,英文为“Natural Language Processing and Chinese Computing”,是中国首个NLP领域的国际会议,由中国计算机学会(CCF)主办,至今已经举办了七届。在今年的竞赛单元中,首次增加了中文语法错误修正任务(Shared Task 2: Grammatical Error Correction)。该项任务的目标是:检测并修正由非中文母语者书写的中文句子中的语法错误[1]。可以认为该项任务的输入是一句可能含有语法错误的中文句子,输出是一句经过修正后的中文句子。作为一个比赛任务,这个工作更关注算法的效果,即结果的正确性,而不太考虑处理速度、资源占用等应用落地的问题。
数据篇
比赛方要求参赛者主要使用主办方提供的数据进行模型算法的训练和调试,在比赛截止前一周发布测试集原文,参赛者使用算法生成指定格式的自动批改结果以后提交结果。 主办方给出的训练数据来源于一个语言学习网站,该网站提供了一个开放平台让对应语言的母语者可以自由地对平台上语言学习者写的作文进行语法修正。训练数据共有71万条记录,每一条记录包含一个可能含有语法错误的句子和零到多句对应句子修正结果。如果是零句修正结果,则可以认为这句话是不需要修正的;如果是多句修正结果,可以认为有多种修改方法。 在一个传统的自然语言处理任务中,训练数据的收集和清洗往往会占到整个策略工作的50%甚至70%的时间,数据预处理的策略也会对后续算法的选择和效果有非常大的影响。通过对训练语料的分析,我们最终使用的策略是:将训练语料中每条记录拆成多个错误到正确的语句对,如果某条记录没有修正结果,则生成一个正确到正确的语句对。经过上述处理后,我们最终获得了122万条训练语料,并且将其中的3000句预留作为调试用的开发集,不参与到训练当中。原始训练数据的对应修正结果分布及样例分别如图表 1和图表 2所示。
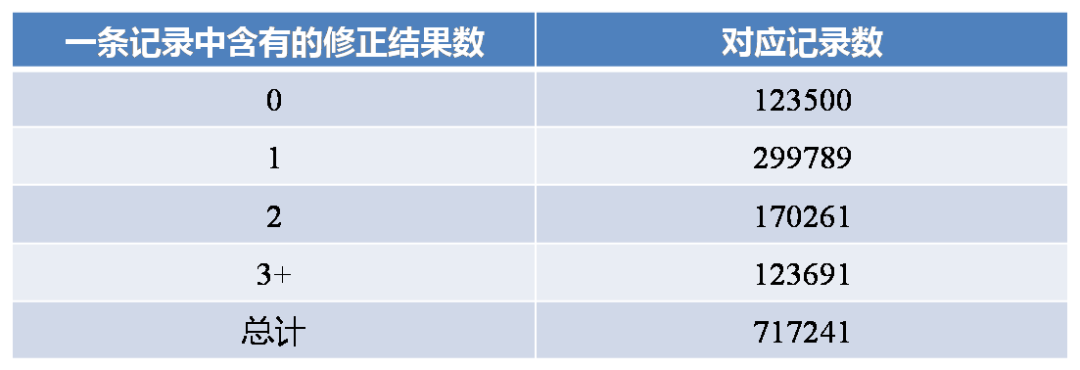
图表1训练数据对应修正结果分布
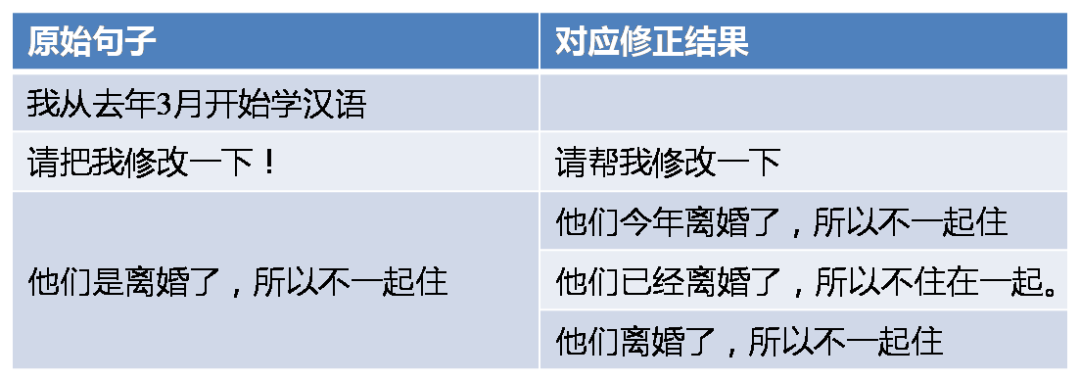
图表2训练数据样例
方法
有多种方法能够处理语法错误修正问题,包括纯粹基于规则的方法、基于多种错误类型的分类器组合方法以及基于机器翻译方法等。机器翻译方法是目前语法错误修正研究领域最为热门和先进的方法,简单的说,它将从原始“错误句子”到修正后“正确句子”的处理过程,看作是一个机器翻译的问题,即将错误的句子翻译成正确的句子。在数据资源更为丰富,研究也更为充分的英文语法错误修正领域,基于神经网络机器翻译的方法已经在CoNLL-2014公开测试集(一个与本次比赛类似但是语言为英语的竞赛任务)上表现出超过人类的修正水平[2]。 基于上述分析和有道在机器翻译领域的多年工作,我们同样采用了神经网络机器翻译的方法来建模这个任务。但是,从第二节的数据分析中可以看出,训练语料规模只有122万,并且存在一定的噪音,而语法错误的类型是多种多样的,当前规模的训练数据并不足以构建一个足够好的中文“翻译”模型。因此,我们设计了一个3阶段方法来处理这个问题,简单的流程描述如图表 3所示。第一个阶段我们将主要处理句子中的浅层错误,第二个阶段处理深层次语法错误,最后一个阶段将上述两个阶段结果进行整合和重排序。
![]()
图表3简单的系统流程
下面将详细介绍3个阶段的处理方法。
阶段一:移除浅层错误
所谓浅层错误,就是诸如拼写错误,标点符号这一类的错误。但是,与英文不同的是,在这个任务场景下,中文没有“错字”,只有因为发音相似或者偏旁相似造成的别字。基于这一原因,我们决定先剔除这部分别字。为了判断哪些字符是相似字符,我们使用了SIGHAN 2013 CSC数据集中的相似字符集(以下简称SCS)[3][4]。这一相似字符集包含发音相似与偏旁相似两部分内容,其内容如图4所示

图4 相似字符集数据示例
阶段二:移除深层次错误
在这一阶段,我们主要采用神经网络机器翻译的方法,将一个含有语法错误的句子翻译成一个语法正确的句子。这一阶段主要分为两个小步骤:1、清洗训练语料,2、构建翻译模型。 1. 清洗训练语料 和机器翻译任务中,希望训练语料为互相翻译的中英句对一样,在当前任务中,我们期望训练语料中的每一个句对都是从错误的句子(“原文”)到正确的句子(“译文”),或者从正确的句子(“原文”)到正确的句子(“保留原样不改变的译文”)。经过对训练数据的抽样查看和分析,我们发现,训练数据中存在大量的噪音,包括但不限于可能错误的修改,混杂表情符号,乱码等。神经网络机器翻译模型对于噪声数据的容忍程度相对是较差的,因此我们首先采用前述提到的语言模型对训练句对进行过滤,移除掉那些语言模型的困惑度明显不符合预期的句对,即,原则上正确的句子(“译文”)应该比错误的句子(“原文”)更流利,困惑度更低。通过这一过滤操作,我们将训练语料对从122w降到了76w。虽然训练数据的整体规模变少了很多,但是质量有了明显的提升。 2. 构建神经网络机器翻译引擎
此处我们采用了目前机器翻译领域取得最佳结果的标准Transformer模型。考虑到汉语表达的特点,一方面很多字是单字成词,另外一方面“别字”问题可能会带来分词的错误,单一基于字或者词(子词)级别的翻译模型都无法全面处理中文语法错误。我们构建了两种不同粒度的翻译模型:第一种是基于字级别的翻译模型,第二种是基于子词级别的翻译模型。由于时间关系,这两个模型本身都是单模型,没有应用上神经网络机器翻译常用的模型融合(ensemble)技术。
阶段三:结果重排序
该阶段组合上述两个阶段的模型并对结果重排序选择最优结果。在这一阶段,我们将阶段一和阶段二所生成的模型进行了组合,构建了以下五个模型: M1: 单一的浅层错误修正模型 M2: 浅层错误修正模型+基于字的翻译模型 M3:浅层错误修正模型+基于子词的翻译模型 M4:浅层错误修正模型+基于字的翻译模型+基于子词的翻译模型 M5:浅层错误修正模型+基于子词的翻译模型+基于字的翻译模型 对于输入句子,我们使用上述五个模型分别生成一个结果,然后利用语言模型对五个结果进行评估,选出最佳结果。具体如图表 5所示。
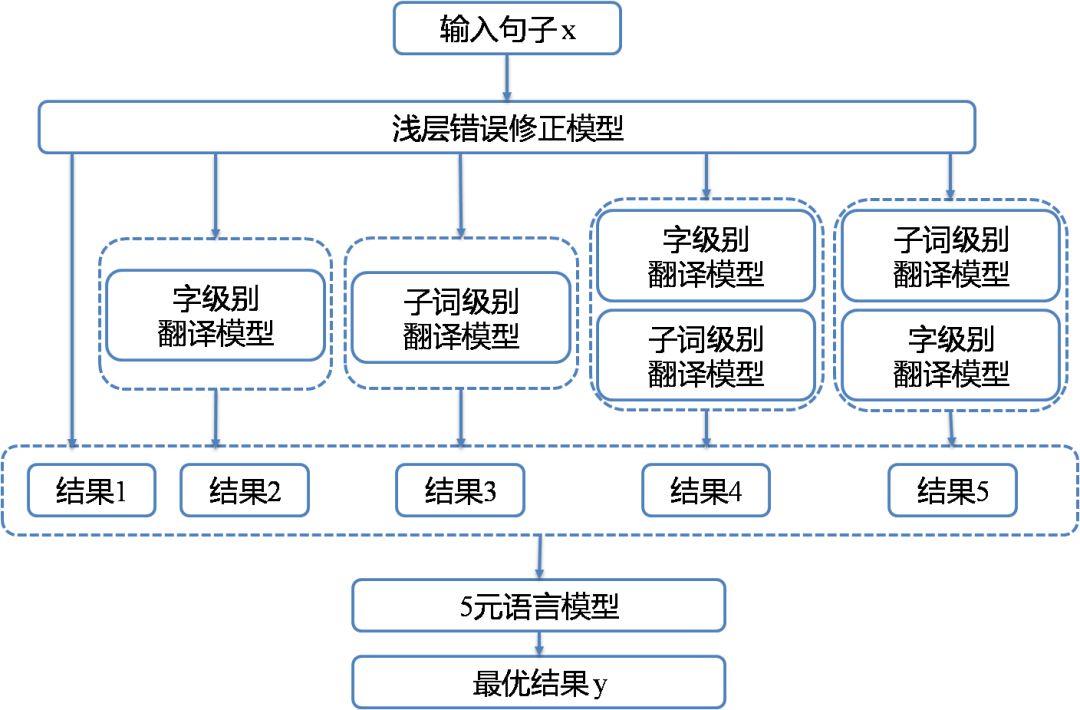
图表5详细流程图
可以看到的是,结果4和结果5将“字级别翻译模型”及“子词级别翻译模型”使用不同的顺序进行了串联,有点类似人在琢磨如何修正一个错误的句子时多次修改和推敲的过程,串联不同粒度的模型有助于系统捕捉到不同粒度的错误。
最终结果
在NLPCC2018的测试集上,我们在包括阿里巴巴团队、北京大学团队在内的实际提交结果的6支队伍中取得了最高的值与最高的召回率[1],具体结果见图表 6所示。
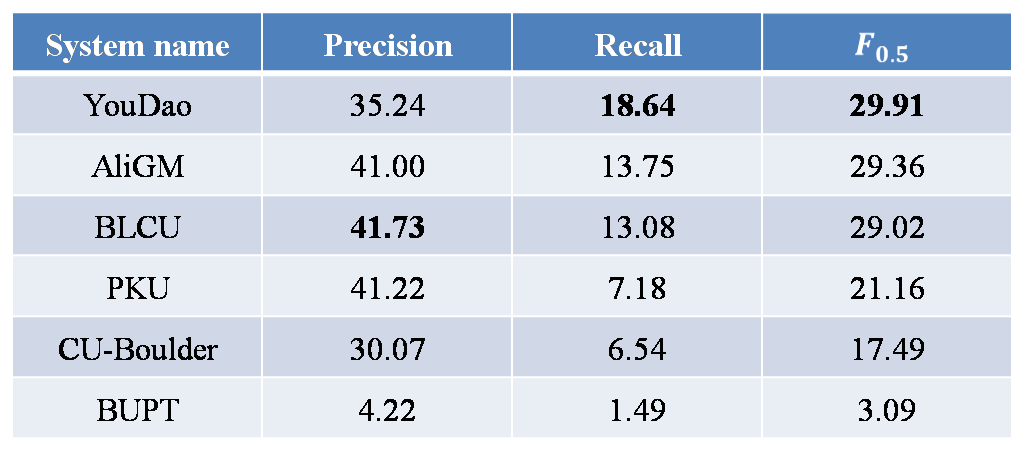
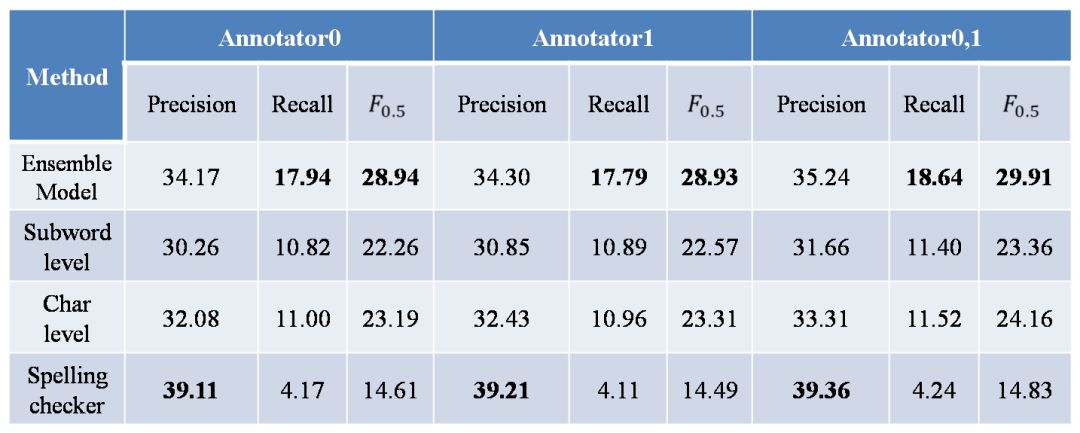
图表7测试集上各子模块独立的结果
后续工作

 微信
微信

 新浪微博
新浪微博

 有道云笔记
有道云笔记